

ダウンロードの自動化を考えよう
この章では、ボートレース(競艇)のデータをダウンロードするやり方を紹介します。
「いやいや、ダウンロードって日付を選んでボタンを押すだけでしょ」
「その通り!(笑)」
いやいやいやいや! 確かに1つ1つのファイルを手作業でダウンロードすることも可能ですが、数ヶ月や数年分ともなれば骨の折れる作業ですよ。
ここではPythonを利用してダウンロードの自動化を考えてみましょう。
今では貴重な築古サイト
まずはボートレースの公式サイトを開いてください。
上のメニューから「データを調べる」→「ダウンロード・他」に進み、下の各種ダウンロードにある「競争成績ダウンロード」をクリックします。
すると、、、「ひえっ!」

これは貴重ですよ。Netscapeはボタンを押してって、何年前の話やねん!(笑)
月を選択するプルダウンメニューを開くと1996年7月から選ぶことができますが、その頃からこのページは存在し、レイアウトも変わっていないのでしょう。
表示域が狭いことから、当時のモニターの解像度が小さかった(恐らく640*480を想定している)ことがうかがえます。
1996年と言うことは、Windows 95が登場したのが1995年ですから、インターネットの黎明期からボートレースのデータが提供されていたことになります。担当者の熱意が感じられますね。
ページのソースをチェックしよう
ダウンロードを自動化するには、ファイルの住所であるURLを調べる必要があります。
ソースを見ると分かるのですが、このページでは今どき珍しいことにフレームが使われています。フレームとは、1つのページの中に複数のページを同時に表示させる機能のことです。
ここではフレームを使ってページを上下に分割し、上側で年月を選択すると下側に日にちのラジオボタン(を持つページ)が表示される仕組みになっています。
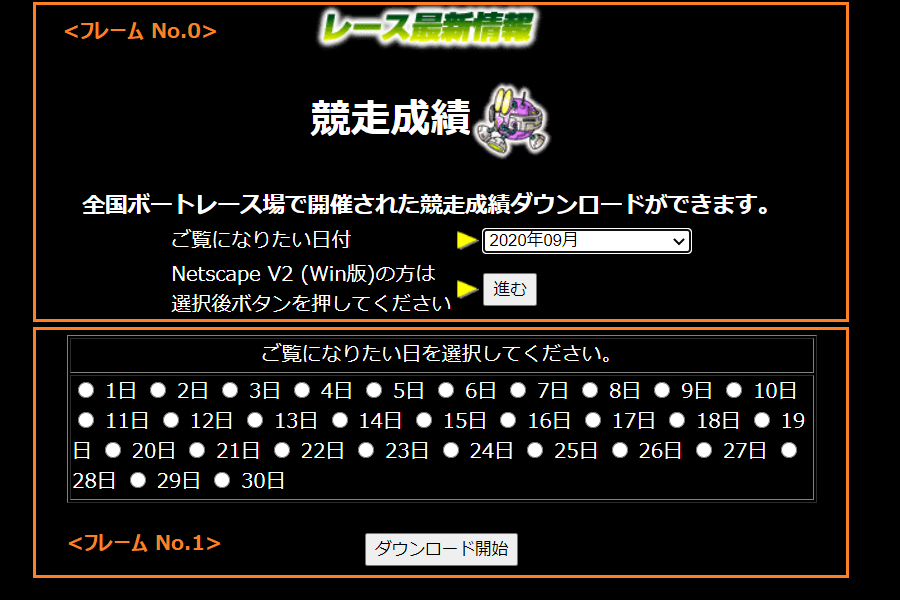
ダウンロードするファイルのURLを調べるには、「ダウンロード開始」ボタンがある下側のフレームに表示されているページのソース(htmlファイルの中身)を確認します。
ソースを見るには、下側のページ上で右クリックし「フレームのソースを表示」をクリックします。Chromeの場合は「検証」でも結構です。
ダウンロードするファイルのURLは、ソースの上部に書かれているJava Scriptが生成しています。その部分を見てみましょう。
コメントはテイモンがスクリプトの解説として追記しました。
<SCRIPT LANGUAGE="JavaScript">
<!--
// 変数dirにベースとなるURLを代入。location.hostはドメイン名
var dir="http://"+location.host+"/od2/K/202009/k2009";
// ダウンロードボタンを押下したときに実行される関数
function download(t){
var i,m;
// 日にちが選択されていない場合
if(t.form.MDAY.length==null){
m = t.form.MDAY.value;
}
// 日にちが選択されている場合
else{
for(i = 0; i < t.form.MDAY.length; i++){
if(t.form.MDAY[i].checked){
// 変数mに選択した日付のvalue(2桁の日付)を代入
m = t.form.MDAY[i].value;
break;
}
}
}
// 変数locationにダウンロードするファイルのURLを代入
location= dir + m + ".lzh";
}
//-->
</SCRIPT>結論としては、上のスクリプトから生成されるURLは次の通りです。
http://www1.mbrace.or.jp/od2/K/202009/k2009 + 2桁の日付 + .lzh年月の部分は、フレームの上部で選択した年月によって変わります。したがって、ダウンロードするファイルのURLのルールは次のようになると考えらえます。
http://www1.mbrace.or.jp/od2/K/YYYYMM/kYYMMDD.lzh
YYYY: 西暦4桁
YY: 西暦下2桁
MM: 月2桁
DD: 日2桁例えば、2020年9月6日のURLは次の通りです。
http://www1.mbrace.or.jp/od2/K/202009/k200906.lzh試しに、このURLをブラウザのURLボックスに貼り付けて実行してみてください。同日の競争成績がダウンロードできますね。
Pythonスクリプトを書いてみよう
URLのルールが分かったところで、いよいよダウンロードを自動化するためのスクリプトを考えてみましょう。ここで紹介するスクリプトは大きく分けて2つの作業をします。
- 指定された期間の日付リストを生成
- リストから日付を取り出してURLを生成しダウンロード
Pythonで日付を扱うには専用のモジュールをインポートする必要があります。ここではdatetimeを使いました。timedeltaと呼ばれる日付型を用いることで、期間を計算することができます。
初心者の人はこの辺りの説明を気にする必要はありません。テイモンのスクリプトには多くのコメントを入れていますので、それらをよく読みスクリプトの流れを理解するようにしましょう。
下のスクリプトの使い方は簡単です。コラボで作成したノートブックのセルに丸っと全部コピペして実行するだけです。コラボについては前の章を参照してください。
スクリプトの上部で期間を指定できるので、そこだけ任意の値に変更しましょう。コラボではなくローカル環境で実行する場合は、保存先も任意の場所に変更してください。それでは動かしてみましょう!
# 開始日と終了日を指定(YYYY-MM-DD)
START_DATE = "2020-09-01"
END_DATE = "2020-09-07"
# ファイルの保存先を指定 ※コラボでGoogleドライブをマウントした状態を想定
SAVE_DIR = "drive/My Drive/results_lzh/"
# リクエスト間隔を指定(秒) ※サーバに負荷をかけないよう3秒以上を推奨
INTERVAL = 3
# URLの固定部分を指定
FIXED_URL = "http://www1.mbrace.or.jp/od2/K/"
# 時間を制御する time モジュールをインポート
from time import sleep
# HTTP通信ライブラリの requests モジュールをインポート
from requests import get
# 日付を扱うための datetime モジュールをインポート
from datetime import datetime as dt
from datetime import timedelta as td
# フォルダ(ディレクトリ)を作成する makedirs モジュールをインポート
from os import makedirs
# 開始合図
print("作業を開始します")
# ファイルを格納するフォルダを作成
makedirs(SAVE_DIR, exist_ok=True)
# 開始日と終了日を日付型に変換して格納
start_date = dt.strptime(START_DATE, '%Y-%m-%d')
end_date = dt.strptime(END_DATE, '%Y-%m-%d')
# 日付の差から期間を計算
days_num = (end_date - start_date).days + 1
# 日付リストを格納する変数
date_list = []
# 日付リストを生成
for i in range(days_num):
# 開始日から日付を順に取得
target_date = start_date + td(days=i)
# 日付型を文字列に変換してリストに格納(YYYYMMDD)
date_list.append(target_date.strftime("%Y%m%d"))
# URL生成とダウンロード
for date in date_list:
# URL生成
yyyymm = date[0:4] + date[4:6]
yymmdd = date[2:4] + date[4:6] + date[6:8]
variable_url = FIXED_URL + yyyymm + "/k" + yymmdd + ".lzh"
file_name = "k" + yymmdd + ".lzh"
# ダウンロード
r = get(variable_url)
# 成功した場合
if r.status_code == 200:
f = open(SAVE_DIR + file_name, 'wb')
f.write(r.content)
f.close()
print(variable_url + " をダウンロードしました")
# 失敗した場合
else:
print(variable_url + " のダウンロードに失敗しました")
# 指定した間隔をあける
sleep(INTERVAL)
# 終了合図
print("作業を終了しました")コラボで実行したとして、うまくいった場合は次のようになります。
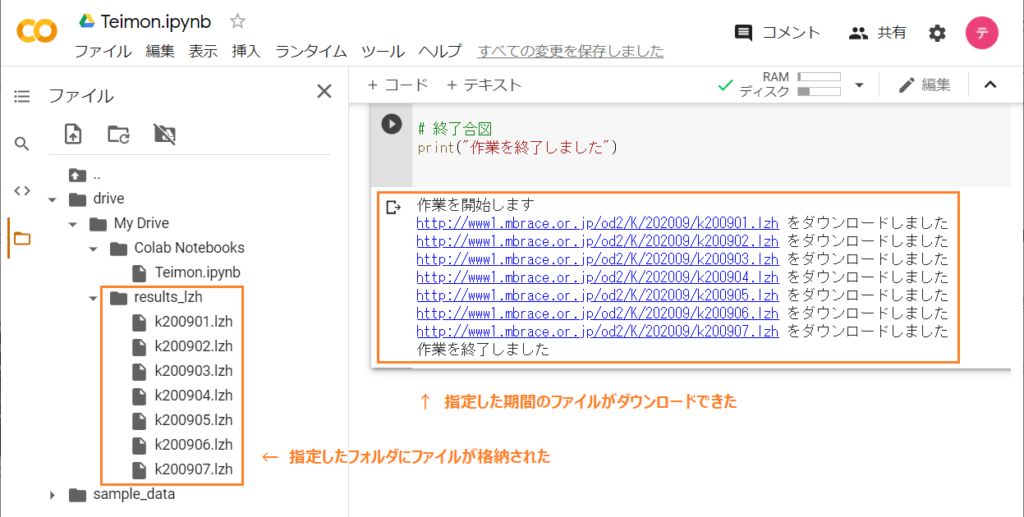
1つ1つのファイルを手作業でダウンロードするよりも圧倒的に効率が良いですね!これで退屈なことをPythonにやらせることができました。
ダウンロードしたファイルはlzh形式で圧縮されていますので、次回はファイルの解凍を自動化することを考えてみましょう。

