

レース違い
やっと番組表の意味が分かったよんっ。それで、○○産駒ってどこに書いてあるの?
キョーコ。今さらだけどボクはボートレースの妖精だからね。あと家族関係なんかは番組表に書いてないから、知りたければこちらの記事を読んで欲しいゾ
そうなんだ。産駒って重要だと思うんだけどなぁ。だって、親が強かったら子も強いし、兄が強かったら弟も強いはずでしょ?
(いい指摘なんだけど、なんかズレてるんだよな…)
固定長データさんいらっしゃい!
ちなみに産駒とは競馬用語で、ある特定の親から生まれた子のことを言います。例えば、大山千広は大山博美産駒といった使い方をします。いや、ボートレーサーには使わないか。。。
さて、前の章で解凍したファイルをGoogleドライブでプレビューしてみましょう。
せーーのっ、ドンッ!

やっぱりこれか、、、でも恐れるに足りません。
このままでは何も分析できない固定長データですが、『コラボでGO!(5)』で競走成績をCSV化した流れと一緒です。ここから必要なデータを抽出していきましょう。
番組表に記録されているデータは重要な情報ばかりです。これらのデータを競走成績と紐づければ、結果に影響している可能性がある項目を比較・検討できます。先のことを考えると番組表のデータは全て抽出した方が良さそうです。
ちなみに、番組表はレース開催前夜に公式サイトからダウンロード可能です。
キーワードを探そう
テキストファイルからデータを抽出するためには、データの位置を特定する必要があります。
固定長データの場合、何行目の何文字目というように絶対位置を指定する方法もありますが、番組表はレース場により日程が異なるため、データの位置が毎日変化します。そこで、番組表に必ず含まれるキーワードを探して、そこから相対位置を指定してデータを抽出します。
まずは番組表ファイルの特徴を見てみましょう。
- 最初と最後の行に特定のキーワードがある
最初の行 →STARTB
最後の行 →FINALB - レース場ごとに番組表がまとめられ、その最初と最後の行に特定のキーワードがある
最初の行 →[場コード] + BBGN
最後の行 →[場コード] + BEND - キーワード「*** 番組表 ***」から下にタイトルなどが記載されている
- キーワード「電話投票締切予定」から下にレース回ごとの情報が記載されている
#1と#2の特徴は、抽出するデータの位置から離れているため扱いづらいです。
番組表ファイルの特徴として、レース回ごとにレーサーのデータがまとまっていますので、そのまとまりの中にあるキーワードを使うのが良いでしょう。そこで、#3と#4の特徴を利用してデータを抜き出すことを考えてみます。

Pythonスクリプトの記述
Pythonスクリプトの動きとしては、次のようになります。
- テキストファイル(番組表)を開く
- 上から順番に読み込み「番組表」というキーワードを見つけたら、そこから相対的な位置を示してタイトルやレース日などを取得
- 次に「電話投票締切予定」というキーワードを見つけたら、その行からレース回やレース名などを取得し、そこから相対的な位置を示してレース回ごとにレーサーの情報を取得
- CSVファイルにレース回ごとにデータを書き込む
- 次のテキストファイル(番組表)を開く
ポイントとして、CSVファイルに書き込む際に「1レコード1レース」として記録することです。テキストファイルでは艇番ごとに1レコードとなっていますが、CSV化する際に1〜6艇分を1レコードにまとめます。なぜでしょうか?
仮に艇番ごとに1レコードとすると、レース回やレース名など重複しますよね。このシリーズの後半で番組表と競走成績のデータを紐づけますが、データが重複していると1:1で紐づかず都合が悪いのです。
データの重複を解消するために「正規化」や「ピボット解除」と呼ばれる方法がありますが、これらについてはまた別の機会にご紹介します。
それでは早速スクリプトを書いていきましょう。
今回のスクリプトが長めですが、これは取得するデータが多いためです。やっていることは競走成績とあまり変わりませんので、慣れるためにもスクリプトを自分の目で追って確認してから実行しましょう。
# 解凍したテキストファイルの格納先を指定
TEXT_FILE_DIR = "drive/My Drive/timetable_txt/"
# CSVファイルの保存先を指定
CSV_FILE_DIR = "drive/My Drive/timetable_csv/"
# CSVファイルの名前を指定 ※YYYYMMDDには対象期間を入力
CSV_FILE_NAME = "timetable_YYYYMMDD-YYYYMMDD.csv"
# CSVファイルのヘッダーを指定
CSV_FILE_HEADER = "タイトル,日次,レース日,レース場,レース回,レース名,距離(m),電話投票締切予定,\
1枠_艇番,1枠_登録番号,1枠_選手名,1枠_年齢,1枠_支部,1枠_体重,1枠_級別,\
1枠_全国勝率,1枠_全国2連対率,1枠_当地勝率,1枠_当地2連対率,\
1枠_モーター番号,1枠_モーター2連対率,1枠_ボート番号,1枠_ボート2連対率,\
1枠_今節成績_1-1,1枠_今節成績_1-2,1枠_今節成績_2-1,1枠_今節成績_2-2,1枠_今節成績_3-1,1枠_今節成績_3-2,\
1枠_今節成績_4-1,1枠_今節成績_4-2,1枠_今節成績_5-1,1枠_今節成績_5-2,1枠_今節成績_6-1,1枠_今節成績_6-2,1枠_早見,\
2枠_艇番,2枠_登録番号,2枠_選手名,2枠_年齢,2枠_支部,2枠_体重,2枠_級別,\
2枠_全国勝率,2枠_全国2連対率,2枠_当地勝率,2枠_当地2連対率,\
2枠_モーター番号,2枠_モーター2連対率,2枠_ボート番号,2枠_ボート2連対率,\
2枠_今節成績_1-1,2枠_今節成績_1-2,2枠_今節成績_2-1,2枠_今節成績_2-2,2枠_今節成績_3-1,2枠_今節成績_3-2,\
2枠_今節成績_4-1,2枠_今節成績_4-2,2枠_今節成績_5-1,2枠_今節成績_5-2,2枠_今節成績_6-1,2枠_今節成績_6-2,2枠_早見,\
3枠_艇番,3枠_登録番号,3枠_選手名,3枠_年齢,3枠_支部,3枠_体重,3枠_級別,\
3枠_全国勝率,3枠_全国2連対率,3枠_当地勝率,3枠_当地2連対率,\
3枠_モーター番号,3枠_モーター2連対率,3枠_ボート番号,3枠_ボート2連対率,\
3枠_今節成績_1-1,3枠_今節成績_1-2,3枠_今節成績_2-1,3枠_今節成績_2-2,3枠_今節成績_3-1,3枠_今節成績_3-2,\
3枠_今節成績_4-1,3枠_今節成績_4-2,3枠_今節成績_5-1,3枠_今節成績_5-2,3枠_今節成績_6-1,3枠_今節成績_6-2,3枠_早見,\
4枠_艇番,4枠_登録番号,4枠_選手名,4枠_年齢,4枠_支部,4枠_体重,4枠_級別,\
4枠_全国勝率,4枠_全国2連対率,4枠_当地勝率,4枠_当地2連対率,\
4枠_モーター番号,4枠_モーター2連対率,4枠_ボート番号,4枠_ボート2連対率,\
4枠_今節成績_1-1,4枠_今節成績_1-2,4枠_今節成績_2-1,4枠_今節成績_2-2,4枠_今節成績_3-1,4枠_今節成績_3-2,\
4枠_今節成績_4-1,4枠_今節成績_4-2,4枠_今節成績_5-1,4枠_今節成績_5-2,4枠_今節成績_6-1,4枠_今節成績_6-2,4枠_早見,\
5枠_艇番,5枠_登録番号,5枠_選手名,5枠_年齢,5枠_支部,5枠_体重,5枠_級別,\
5枠_全国勝率,5枠_全国2連対率,5枠_当地勝率,5枠_当地2連対率,\
5枠_モーター番号,5枠_モーター2連対率,5枠_ボート番号,5枠_ボート2連対率,\
5枠_今節成績_1-1,5枠_今節成績_1-2,5枠_今節成績_2-1,5枠_今節成績_2-2,5枠_今節成績_3-1,5枠_今節成績_3-2,\
5枠_今節成績_4-1,5枠_今節成績_4-2,5枠_今節成績_5-1,5枠_今節成績_5-2,5枠_今節成績_6-1,5枠_今節成績_6-2,5枠_早見,\
6枠_艇番,6枠_登録番号,6枠_選手名,6枠_年齢,6枠_支部,6枠_体重,6枠_級別,\
6枠_全国勝率,6枠_全国2連対率,6枠_当地勝率,6枠_当地2連対率,\
6枠_モーター番号,6枠_モーター2連対率,6枠_ボート番号,6枠_ボート2連対率,\
6枠_今節成績_1-1,6枠_今節成績_1-2,6枠_今節成績_2-1,6枠_今節成績_2-2,6枠_今節成績_3-1,6枠_今節成績_3-2,\
6枠_今節成績_4-1,6枠_今節成績_4-2,6枠_今節成績_5-1,6枠_今節成績_5-2,6枠_今節成績_6-1,6枠_今節成績_6-2,6枠_早見\n"
# OSの機能を利用するパッケージ os をインポート
import os
# 正規表現をサポートするモジュール re をインポート
import re
# テキストファイルからデータを抽出し、CSVファイルに書き込む関数 get_data を定義
def get_data(text_file):
# CSVファイルを追記モードで開く
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "a", encoding="shift_jis")
# テキストファイルから中身を順に取り出す
for contents in text_file:
# キーワード「番組表」を見つけたら(rは正規表現でraw文字列を指定するおまじない)
if re.search(r"番組表", contents):
# 1行スキップ
text_file.readline()
# タイトルを格納
line = text_file.readline()
title = line[:-1].strip()
# 1行スキップ
text_file.readline()
# 日次・レース日・レース場を格納
line = text_file.readline()
day = line[3:7]
date = line[17:28]
stadium = line[52:55]
# キーワード「電話投票締切予定」を見つけたら
if re.search(r"電話投票締切予定", contents):
# キーワードを見つけた行を格納
line = contents
# レース名にキーワード「進入固定」が割り込んだ際の補正(「進入固定戦隊」は除くためHまで含めて置換)
if re.search(r"進入固定", line):
line = line.replace('進入固定 H', '進入固定 H')
# レース回・レース名・距離(m)・電話投票締切予定を格納
race_round = line[0:3]
race_name = line[5:21]
distance = line[22:26]
post_time = line[37:42]
# 4行スキップ(ヘッダー部分)
text_file.readline()
text_file.readline()
text_file.readline()
text_file.readline()
# 選手データを格納する変数を定義
racer_data = ""
# 選手データを読み込む行(開始行)を格納
line = text_file.readline()
# 空行またはキーワード「END」まで処理を繰り返す = 1~6艇分の選手データを取得
while line != "\n":
if re.search(r"END", line):
break
# 選手データを格納(行末にカンマが入らないように先頭にカンマを入れる)
racer_data += "," + line[0] + "," + line[2:6] + "," + line[6:10] + "," + line[10:12] \
+ "," + line[12:14] + "," + line[14:16] + "," + line[16:18] \
+ "," + line[19:23] + "," + line[24:29] + "," + line[30:34] \
+ "," + line[35:40] + "," + line[41:43] + "," + line[44:49] \
+ "," + line[50:52] + "," + line[53:58] + "," + line[59:60] \
+ "," + line[60:61] + "," + line[61:62] + "," + line[62:63] \
+ "," + line[63:64] + "," + line[64:65] + "," + line[65:66] \
+ "," + line[66:67] + "," + line[67:68] + "," + line[68:69] \
+ "," + line[69:70] + "," + line[70:71] + "," + line[71:73]
# 次の行を読み込む
line = text_file.readline()
# 抽出したデータをCSVファイルに書き込む
csv_file.write(title + "," + day + "," + date + "," + stadium + "," + race_round
+ "," + race_name + "," + distance + "," + post_time + racer_data + "\n")
# CSVファイルを閉じる
csv_file.close()
# 開始合図
print("作業を開始します")
# CSVファイルを保存するフォルダを作成
os.makedirs(CSV_FILE_DIR, exist_ok=True)
# CSVファイルを作成しヘッダ情報を書き込む
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "w", encoding="shift_jis")
csv_file.write(CSV_FILE_HEADER)
csv_file.close()
# テキストファイルのリストを取得
text_file_list = os.listdir(TEXT_FILE_DIR)
# リストからファイル名を順に取り出す
for text_file_name in text_file_list:
# 拡張子が TXT のファイルに対してのみ実行
if re.search(".TXT", text_file_name):
# テキストファイルを開く
text_file = open(TEXT_FILE_DIR + text_file_name, "r", encoding="shift_jis")
# 関数 get_data にファイル(オブジェクト)を渡す
get_data(text_file)
# テキストファイルを閉じる
text_file.close()
print(CSV_FILE_DIR + CSV_FILE_NAME + " を作成しました")
# 終了合図
print("作業を終了しました")
なにかおかしい
上記のスクリプトをコラボに貼り付けて実行すると、ダウンロードした番組表をCSV化してくれます。できたファイルをGoogleドライブでプレビューしてみましょう。
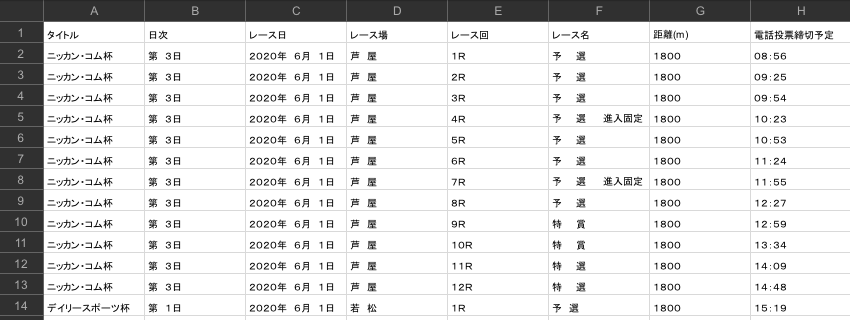
さて、いかがでしょうか。一見するときれいに抽出できているように見えますが、ちょっと怪しくないですか?
次回はデータの整形方法について解説します。

