

ビッグ
データ量が多いとスプレッドシートやExcelの再計算に時間がかかって大変だよね。そんな時はどうするの?
(珍しくまともな質問だな…) データの前処理が重要になるよ。ビッグデータはビッグなままだと扱いづらいんだ。
そうか!私もボートレースでビッグになってお母さんを見返してやるんだ。
(キョーコがお母さんに呆れられている理由は分かる気がする…)
データの前処理
ボートレースの公式サイトでは、競走成績と番組表のファイルを1996年7月分からダウンロードできます。何十年ものデータを扱うケースはあまりないと思いますが、やろうと思えば大量のデータ(ビッグデータ)を集計することができます。
しかし、テイモンも助言しているようにビッグデータはビッグなままだと扱いづらいです。
例えば、Excelで大量のデータにVLOOKUP関数を適用させると、再計算に時間がかかることがあります。また、データに空白が含まれていると、参照するときにエラーが発生することがあります。
ビッグデータをうまく扱うには、こうした不具合を事前に取り除いておくことが重要です。これをデータの前処理と言います。
ETL処理とは
ETLは抽出・変換・ロードの略で、前処理の手順を示した言葉です。ETLに似た言葉にELTがありますが、これはEvery Little Thingの略ではなく(笑)、変換とロードを逆にしたものです。
| “E” | Extract | 抽出 | 分析に必要なデータを抽出 |
| “T” | Transform | 変換 | 分析に適した形にデータを整形 |
| “L” | Load | ロード | 分析するアプリでデータを読み込む |
ETL処理を支援するアプリをETLツールと呼びます。ExcelにはETLツールとしてPower Queryという機能が備わっています。これについてはまた別の機会にご紹介したいと思います。
Pythonでやっておくこと
前回の『もっとコラボでGO!(3)』では、テキストファイルから必要なデータを「抽出」し、CSV形式に「変換」しましたね。まさにETL処理のEとTを実行したことになります。
しかし、これをスプレッドシートで「ロード」してみると、そのままでは分析できないデータがあることに気がつきましたか?
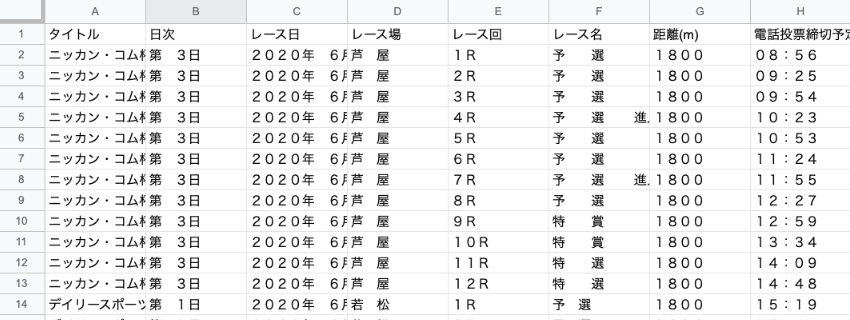
そうです!数字が全角になっていたり、不要なスペースが含まれていますね(*)。これらを前処理せずに読み込んでしまうと、例えばレース日が日付型として認識されず、ロードしてから面倒なことになります。
ロードしてからデータを整形する、つまりETLではなくELT処理をすると、ロードしたアプリ側の負担が大きくなります。ロードする前に整形しておくことで、後の処理が楽になるわけです。
ここでは、次の部分ついてデータの前処理を施してみましょう。
| 列名 | 前処理(ETLの”T”) | 変換前 | 変換後 |
| 日次 | 全角を半角に変換し、スペースを除く | 第 3日 | 第3日 |
| レース日 | 全角を半角に変換し、スペースを0に変換 | 2020年 6月 1日 | 2020年06 月01日 |
| レース場 | スペースを除く | 芦 屋 | 芦屋 |
| レース回 | 全角を半角に変換し、スペースを0に変換 | 1R | 01R |
| レース名 | スペースを除く | 予 選 | 予選 |
| 距離(m) | 全角を半角に変換 | 1800 | 1800 |
| 電話投票締切予定 | 全角を半角に変換 | 08:56 | 08:56 |
なお、前処理の際は各列のデータが質的変数(区別を目的とした変数)なのか量的変数(計算を目的とした変数)なのか、レポートにした時の見た目がどうなるかなどを意識することもポイントです。
(*) Excelやスプレッドシートでそのまま読み込むと、アプリ側がデータの型を判断して変換するため、距離や時間が半角になって表示される場合があります。しかし、テキストエディタなどで読み込むと、元のデータは全角になっていることが分かります。
Pythonで文字列を置換
ここでは、Pythonで文字を置換する方法を説明します。
Excelでは、全角を半角に変換する関数としてASC(アスキー)があります。しかし、Pythonにはそのような都合の良い関数は用意されていません。そこで、変換テーブルを用いて文字を置換する方法を利用します。
# 変換テーブルを定義
trans_asc = str.maketrans('1234567890R: ', '1234567890R: ')
# 変換テーブルを用いて文字列を置換
day = line[3:7].translate(trans_asc)str.maketransの第1引数が変換前の文字(全角)、第2引数が変換後の文字(半角)です。この変換テーブルでは、番組表のデータに存在する可能性のある英数字と記号だけを並べています。
次に、スペースを除く(または任意の文字に置換する)方法としてreplaceを紹介します。メソッドは重ねて書くことができるため、translateの後に続けて記述します。
# 変換テーブルを用いて文字列を置換し、スペースを除く
day = line[3:7].translate(trans_asc).replace(' ','')replaceの第1引数は変換前の文字(スペース)、第2引数が変換後の文字(空欄)です。0に置換する場合は第2引数に0と入れます。
予定していた7ヶ所に適用すると、次のようになります。
# 日次・レース日・レース場を格納
day = line[3:7].translate(trans_asc).replace(' ','')
date = line[17:28].translate(trans_asc).replace(' ','0')
stadium = line[52:55].replace(' ','')
# レース回・レース名・距離(m)・電話投票締切予定を格納
race_round = line[0:3].translate(trans_asc).replace(' ','0')
race_name = line[5:21].replace(' ','')
distance = line[22:26].translate(trans_asc)
post_time = line[37:42].translate(trans_asc)「進入固定」の割り込みに対応
前回の『もっとコラボでGO!(3)』のPythonスクリプトの中に、最初から入れていた前処理があります。これについて解説しておきます。
# レース名にキーワード「進入固定」が割り込んだ際の補正(「進入固定戦隊」は除くためHまで含めて置換)
if re.search(r"進入固定", line):
line = line.replace('進入固定 H', '進入固定 H')「進入固定」とは、各艇が枠番通りにスタートコースに進入することを義務づけているレースです。
進入固定レース自体は問題ないのですが、レース名に「進入固定」が入ると固定長データの文字の位置がズレます。レース名だけがズレるなら問題ないのですが、それ以降のデータの位置もズレてしまうんです。
具体的には、「進入固定」の文字列が割り込むとレース名に使われているバイトの長さが短くなります。そこで、割り込んだ際にはスペースを加えておく処理を施し、以降のデータに影響が出ないようにするのが上のスクリプトです。
このような処理を適切に行うためには、データをじっくり眺めてみることが大切です。
Pythonスクリプトの記述
それでは、最後に番組表に前処理を施したスクリプトを記載しておきます。CSVファイルの保存先と、上で紹介した文字列操作の部分を更新しています。コラボに貼り付けて実行してみましょう。
# 解凍したテキストファイルの格納先を指定
TEXT_FILE_DIR = "drive/My Drive/timetable_txt/"
# CSVファイルの保存先を指定
CSV_FILE_DIR = "drive/My Drive/timetable_csv_etl/"
# CSVファイルの名前を指定 ※YYYYMMDDには対象期間を入力
CSV_FILE_NAME = "timetable_YYYYMMDD-YYYYMMDD.csv"
# CSVファイルのヘッダーを指定
CSV_FILE_HEADER = "タイトル,日次,レース日,レース場,レース回,レース名,距離(m),電話投票締切予定,\
1枠_艇番,1枠_登録番号,1枠_選手名,1枠_年齢,1枠_支部,1枠_体重,1枠_級別,\
1枠_全国勝率,1枠_全国2連対率,1枠_当地勝率,1枠_当地2連対率,\
1枠_モーター番号,1枠_モーター2連対率,1枠_ボート番号,1枠_ボート2連対率,\
1枠_今節成績_1-1,1枠_今節成績_1-2,1枠_今節成績_2-1,1枠_今節成績_2-2,1枠_今節成績_3-1,1枠_今節成績_3-2,\
1枠_今節成績_4-1,1枠_今節成績_4-2,1枠_今節成績_5-1,1枠_今節成績_5-2,1枠_今節成績_6-1,1枠_今節成績_6-2,1枠_早見,\
2枠_艇番,2枠_登録番号,2枠_選手名,2枠_年齢,2枠_支部,2枠_体重,2枠_級別,\
2枠_全国勝率,2枠_全国2連対率,2枠_当地勝率,2枠_当地2連対率,\
2枠_モーター番号,2枠_モーター2連対率,2枠_ボート番号,2枠_ボート2連対率,\
2枠_今節成績_1-1,2枠_今節成績_1-2,2枠_今節成績_2-1,2枠_今節成績_2-2,2枠_今節成績_3-1,2枠_今節成績_3-2,\
2枠_今節成績_4-1,2枠_今節成績_4-2,2枠_今節成績_5-1,2枠_今節成績_5-2,2枠_今節成績_6-1,2枠_今節成績_6-2,2枠_早見,\
3枠_艇番,3枠_登録番号,3枠_選手名,3枠_年齢,3枠_支部,3枠_体重,3枠_級別,\
3枠_全国勝率,3枠_全国2連対率,3枠_当地勝率,3枠_当地2連対率,\
3枠_モーター番号,3枠_モーター2連対率,3枠_ボート番号,3枠_ボート2連対率,\
3枠_今節成績_1-1,3枠_今節成績_1-2,3枠_今節成績_2-1,3枠_今節成績_2-2,3枠_今節成績_3-1,3枠_今節成績_3-2,\
3枠_今節成績_4-1,3枠_今節成績_4-2,3枠_今節成績_5-1,3枠_今節成績_5-2,3枠_今節成績_6-1,3枠_今節成績_6-2,3枠_早見,\
4枠_艇番,4枠_登録番号,4枠_選手名,4枠_年齢,4枠_支部,4枠_体重,4枠_級別,\
4枠_全国勝率,4枠_全国2連対率,4枠_当地勝率,4枠_当地2連対率,\
4枠_モーター番号,4枠_モーター2連対率,4枠_ボート番号,4枠_ボート2連対率,\
4枠_今節成績_1-1,4枠_今節成績_1-2,4枠_今節成績_2-1,4枠_今節成績_2-2,4枠_今節成績_3-1,4枠_今節成績_3-2,\
4枠_今節成績_4-1,4枠_今節成績_4-2,4枠_今節成績_5-1,4枠_今節成績_5-2,4枠_今節成績_6-1,4枠_今節成績_6-2,4枠_早見,\
5枠_艇番,5枠_登録番号,5枠_選手名,5枠_年齢,5枠_支部,5枠_体重,5枠_級別,\
5枠_全国勝率,5枠_全国2連対率,5枠_当地勝率,5枠_当地2連対率,\
5枠_モーター番号,5枠_モーター2連対率,5枠_ボート番号,5枠_ボート2連対率,\
5枠_今節成績_1-1,5枠_今節成績_1-2,5枠_今節成績_2-1,5枠_今節成績_2-2,5枠_今節成績_3-1,5枠_今節成績_3-2,\
5枠_今節成績_4-1,5枠_今節成績_4-2,5枠_今節成績_5-1,5枠_今節成績_5-2,5枠_今節成績_6-1,5枠_今節成績_6-2,5枠_早見,\
6枠_艇番,6枠_登録番号,6枠_選手名,6枠_年齢,6枠_支部,6枠_体重,6枠_級別,\
6枠_全国勝率,6枠_全国2連対率,6枠_当地勝率,6枠_当地2連対率,\
6枠_モーター番号,6枠_モーター2連対率,6枠_ボート番号,6枠_ボート2連対率,\
6枠_今節成績_1-1,6枠_今節成績_1-2,6枠_今節成績_2-1,6枠_今節成績_2-2,6枠_今節成績_3-1,6枠_今節成績_3-2,\
6枠_今節成績_4-1,6枠_今節成績_4-2,6枠_今節成績_5-1,6枠_今節成績_5-2,6枠_今節成績_6-1,6枠_今節成績_6-2,6枠_早見\n"
# OSの機能を利用するパッケージ os をインポート
import os
# 正規表現をサポートするモジュール re をインポート
import re
# テキストファイルからデータを抽出し、CSVファイルに書き込む関数 get_data を定義
def get_data(text_file):
# CSVファイルを追記モードで開く
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "a", encoding="shift_jis")
# テキストファイルから中身を順に取り出す
for contents in text_file:
trans_asc = str.maketrans('1234567890R: ', '1234567890R: ')
# キーワード「番組表」を見つけたら(rは正規表現でraw文字列を指定するおまじない)
if re.search(r"番組表", contents):
# 1行スキップ
text_file.readline()
# タイトルを格納
line = text_file.readline()
title = line[:-1].strip()
# 1行スキップ
text_file.readline()
# 日次・レース日・レース場を格納
line = text_file.readline()
day = line[3:7].translate(trans_asc).replace(' ', '')
date = line[17:28].translate(trans_asc).replace(' ', '0')
stadium = line[52:55].replace(' ', '')
# キーワード「電話投票締切予定」を見つけたら
if re.search(r"電話投票締切予定", contents):
# キーワードを見つけた行を格納
line = contents
# レース名にキーワード「進入固定」が割り込んだ際の補正(「進入固定戦隊」は除くためHまで含めて置換)
if re.search(r"進入固定", line):
line = line.replace('進入固定 H', '進入固定 H')
# レース回・レース名・距離(m)・電話投票締切予定を格納
race_round = line[0:3].translate(trans_asc).replace(' ', '0')
race_name = line[5:21].replace(' ', '')
distance = line[22:26].translate(trans_asc)
post_time = line[37:42].translate(trans_asc)
# 4行スキップ(ヘッダー部分)
text_file.readline()
text_file.readline()
text_file.readline()
text_file.readline()
# 選手データを格納する変数を定義
racer_data = ""
# 選手データを読み込む行(開始行)を格納
line = text_file.readline()
# 空行またはキーワード「END」まで処理を繰り返す = 1~6艇分の選手データを取得
while line != "\n":
if re.search(r"END", line):
break
# 選手データを格納(行末にカンマが入らないように先頭にカンマを入れる)
racer_data += "," + line[0] + "," + line[2:6] + "," + line[6:10] + "," + line[10:12] \
+ "," + line[12:14] + "," + line[14:16] + "," + line[16:18] \
+ "," + line[19:23] + "," + line[24:29] + "," + line[30:34] \
+ "," + line[35:40] + "," + line[41:43] + "," + line[44:49] \
+ "," + line[50:52] + "," + line[53:58] + "," + line[59:60] \
+ "," + line[60:61] + "," + line[61:62] + "," + line[62:63] \
+ "," + line[63:64] + "," + line[64:65] + "," + line[65:66] \
+ "," + line[66:67] + "," + line[67:68] + "," + line[68:69] \
+ "," + line[69:70] + "," + line[70:71] + "," + line[71:73]
# 次の行を読み込む
line = text_file.readline()
# 抽出したデータをCSVファイルに書き込む
csv_file.write(title + "," + day + "," + date + "," + stadium + "," + race_round
+ "," + race_name + "," + distance + "," + post_time + racer_data + "\n")
# CSVファイルを閉じる
csv_file.close()
# 開始合図
print("作業を開始します")
# CSVファイルを保存するフォルダを作成
os.makedirs(CSV_FILE_DIR, exist_ok=True)
# CSVファイルを作成しヘッダ情報を書き込む
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "w", encoding="shift_jis")
csv_file.write(CSV_FILE_HEADER)
csv_file.close()
# テキストファイルのリストを取得
text_file_list = os.listdir(TEXT_FILE_DIR)
# リストからファイル名を順に取り出す
for text_file_name in text_file_list:
# 拡張子が TXT のファイルに対してのみ実行
if re.search(".TXT", text_file_name):
# テキストファイルを開く
text_file = open(TEXT_FILE_DIR + text_file_name, "r", encoding="shift_jis")
# 関数 get_data にファイル(オブジェクト)を渡す
get_data(text_file)
# テキストファイルを閉じる
text_file.close()
print(CSV_FILE_DIR + CSV_FILE_NAME + " を作成しました")
# 終了合図
print("作業を終了しました")
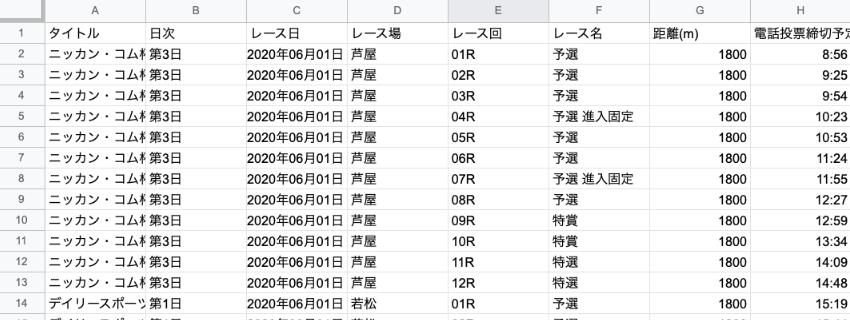
作成したCSVファイルをGoogleスプレッドシートで読み込んでみましょう。下図の通り、うまく前処理されましたね。
次回は前処理の続きとして「レースコード」について紹介します。

