

勝手なイメージ
テイモン!今度一緒に雪山行こうよ。今年の雪は去年より期待できそうだよ
ボクは山よりも海とか川の方が好きなんだけど。。。
あれ?流氷の上でゴロゴロしたりしてるでしょ?どちらかと言うと夏よりも冬の方が好きだと思ってた。
(そういう写真を撮られることが多いだけなんだけどな…)
主キーとはなんぞや?
ボートレースは年中無休、冬でもレースがあります。三国(福井)や桐生(群馬)は特にしばれるだろうな、、、レーサーの皆さまお疲れさまです。
さて、番組表には様々なデータが含まれていますが、番組表だけを使って分析してもあまり意味がありません。ボートレースの結果を予想するには、番組表と競走成績を紐づける必要があります。
2つのテーブル(データを縦と横に並べたもの)を紐づけるには、それぞれのテーブルにレースを特定する情報が必要です。レースを特定するには、レース日・レース場・レース回の3つのデータがあれば良いのですが、幸い番組表にも競走成績にもこれらのデータが存在します。
しかし、3つのデータは列が別れているため扱いづらいです。そこで、これらのデータから「レースコード」を作成し、それを番組表と競走成績の両方のテーブルに持たせることで、簡単にデータを結びつけられるようにします。
このレースコードは、テーブルの各レコードを重複のない1つのデータとして示すものです。これを主キー(プライマリキー項目)と呼びます。主キーは表の中で重複しない項目と覚えておきましょう。
主キーの役割
主キーは、データをまとめるために存在します。別の言い方をすると、データを集計するために設定するものです。
コラボでGO!(6)では、Pivotテーブルを利用して競走成績のファイルからレース場ごとに1-2-3ボックスの発生率を計算しましたが、これはレース場を主キーと見立てて集計したものです。
主キーは、このように1:多の関係(1つ項目に複数の項目が紐づく)を持たせることが本来の役割です。今回は番組表と競走成績それぞれに主キーが存在するため、1:1の関係になります。
ちなみに、スプレッドシートのPivotテーブルは、データを集計するツールとして大変便利なのですが、データの範囲として設定できるのは1つのテーブルだけです。
2つ以上のテーブルを紐づけて集計するには、テーブル間にリレーションシップを設定する必要があります。ExcelではPower Pivotで実現できますが、これについてはまた別の機会にご紹介します。
レースコードの形式
それでは、実際にどのようなレースコードを振るのが良いでしょうか。2020年6月1日の芦屋の第1レースにコードを振ると仮定して考えてみましょう。
| レース日 | レース場 | レース回 | 例 | |
| 候補1 | YYYYMMDD | 場コード | NN | 202006012101 |
| 候補2 | YYYYMMDD | 3レターコード | NN | 20200601ASY01 |
上の2つの候補は、レース場の表記の仕方だけが異なります。レース場には場コードというものが設定されており、これを利用したものが候補1です。場コードの代わりに場ごとに3レターコードを設定したものが候補2になります。
既に知られているコードという点では、候補1の方が良さそうです。しかし、数字の羅列だけではこれが芦屋のレースであることをすぐに認識できませんね。
テイモンは見てすぐ分かるコードをオススメします。候補2であればパッと見て、レース日・レース場・レース回が認識できそうです。3レターコードは以下の通りに振ります。
| 場コード | レース場 | 3レターコード | 場コード | レース場 | 3レターコード | 場コード | レース場 | 3レターコード |
| 01 | 桐生 | KRY | 09 | 津 | TSU | 17 | 宮島 | MYJ |
| 02 | 戸田 | TDA | 10 | 三国 | MKN | 18 | 徳山 | TKY |
| 03 | 江戸川 | EDG | 11 | びわこ | BWK | 19 | 下関 | SMS |
| 04 | 平和島 | HWJ | 12 | 住之江 | SME | 20 | 若松 | WKM |
| 05 | 多摩川 | TMG | 13 | 尼崎 | AMG | 21 | 芦屋 | ASY |
| 06 | 浜名湖 | HMN | 14 | 鳴門 | NRT | 22 | 福岡 | FKO |
| 07 | 蒲郡 | GMG | 15 | 丸亀 | MRG | 23 | 唐津 | KRT |
| 08 | 常滑 | TKN | 16 | 児島 | KJM | 24 | 大村 | OMR |
Pythonでレースコードを振る
それではスクリプトに手を加えていきます。
日付はdate変数に代入した値、レース回はrace_round変数に代入した値をそれぞれ流用できますので、これらの変数からレースコードに利用する部分を抜き出します。
レース場を3レターコードに変換するには辞書を定義します。キーにレース場、値に3レターコードをそれぞれ設定します。
# レースコードを生成
dict_stadium = {'桐生': 'KRY', '戸田': 'TDA', '江戸川': 'EDG', '平和島': 'HWJ',
'多摩川': 'TMG', '浜名湖': 'HMN', '蒲郡': 'GMG', '常滑': 'TKN',
'津': 'TSU', '三国': 'MKN', '琵琶湖': 'BWK', '住之江': 'SME',
'尼崎': 'AMG', '鳴門': 'NRT', '丸亀': 'MRG', '児島': 'KJM',
'宮島': 'MYJ', '徳山': 'TKY', '下関': 'SMS', '若松': 'WKM',
'芦屋': 'ASY', '福岡': 'FKO', '唐津': 'KRT', '大村': 'OMR'
}
race_code = date[0:4] + date[5:7] + date[8:10] + dict_stadium[stadium] + race_round[0:2]レースコードは今後よく使うことになるので、最初の列に挿入しましょう。ヘッダー情報に加えることも忘れずに。
Pythonスクリプトの記述(番組表)
それでは完成版の番組表です。コラボに貼り付けて実行してみましょう。
# 解凍したテキストファイルの格納先を指定
TEXT_FILE_DIR = "drive/My Drive/timetable_txt/"
# CSVファイルの保存先を指定
CSV_FILE_DIR = "drive/My Drive/timetable_csv_racecode/"
# CSVファイルの名前を指定 ※YYYYMMDDには対象期間を入力
CSV_FILE_NAME = "timetable_YYYYMMDD-YYYYMMDD.csv"
# CSVファイルのヘッダーを指定
CSV_FILE_HEADER = "レースコード,タイトル,日次,レース日,レース場,レース回,レース名,距離(m),電話投票締切予定,\
1枠_艇番,1枠_登録番号,1枠_選手名,1枠_年齢,1枠_支部,1枠_体重,1枠_級別,\
1枠_全国勝率,1枠_全国2連対率,1枠_当地勝率,1枠_当地2連対率,\
1枠_モーター番号,1枠_モーター2連対率,1枠_ボート番号,1枠_ボート2連対率,\
1枠_今節成績_1-1,1枠_今節成績_1-2,1枠_今節成績_2-1,1枠_今節成績_2-2,1枠_今節成績_3-1,1枠_今節成績_3-2,\
1枠_今節成績_4-1,1枠_今節成績_4-2,1枠_今節成績_5-1,1枠_今節成績_5-2,1枠_今節成績_6-1,1枠_今節成績_6-2,1枠_早見,\
2枠_艇番,2枠_登録番号,2枠_選手名,2枠_年齢,2枠_支部,2枠_体重,2枠_級別,\
2枠_全国勝率,2枠_全国2連対率,2枠_当地勝率,2枠_当地2連対率,\
2枠_モーター番号,2枠_モーター2連対率,2枠_ボート番号,2枠_ボート2連対率,\
2枠_今節成績_1-1,2枠_今節成績_1-2,2枠_今節成績_2-1,2枠_今節成績_2-2,2枠_今節成績_3-1,2枠_今節成績_3-2,\
2枠_今節成績_4-1,2枠_今節成績_4-2,2枠_今節成績_5-1,2枠_今節成績_5-2,2枠_今節成績_6-1,2枠_今節成績_6-2,2枠_早見,\
3枠_艇番,3枠_登録番号,3枠_選手名,3枠_年齢,3枠_支部,3枠_体重,3枠_級別,\
3枠_全国勝率,3枠_全国2連対率,3枠_当地勝率,3枠_当地2連対率,\
3枠_モーター番号,3枠_モーター2連対率,3枠_ボート番号,3枠_ボート2連対率,\
3枠_今節成績_1-1,3枠_今節成績_1-2,3枠_今節成績_2-1,3枠_今節成績_2-2,3枠_今節成績_3-1,3枠_今節成績_3-2,\
3枠_今節成績_4-1,3枠_今節成績_4-2,3枠_今節成績_5-1,3枠_今節成績_5-2,3枠_今節成績_6-1,3枠_今節成績_6-2,3枠_早見,\
4枠_艇番,4枠_登録番号,4枠_選手名,4枠_年齢,4枠_支部,4枠_体重,4枠_級別,\
4枠_全国勝率,4枠_全国2連対率,4枠_当地勝率,4枠_当地2連対率,\
4枠_モーター番号,4枠_モーター2連対率,4枠_ボート番号,4枠_ボート2連対率,\
4枠_今節成績_1-1,4枠_今節成績_1-2,4枠_今節成績_2-1,4枠_今節成績_2-2,4枠_今節成績_3-1,4枠_今節成績_3-2,\
4枠_今節成績_4-1,4枠_今節成績_4-2,4枠_今節成績_5-1,4枠_今節成績_5-2,4枠_今節成績_6-1,4枠_今節成績_6-2,4枠_早見,\
5枠_艇番,5枠_登録番号,5枠_選手名,5枠_年齢,5枠_支部,5枠_体重,5枠_級別,\
5枠_全国勝率,5枠_全国2連対率,5枠_当地勝率,5枠_当地2連対率,\
5枠_モーター番号,5枠_モーター2連対率,5枠_ボート番号,5枠_ボート2連対率,\
5枠_今節成績_1-1,5枠_今節成績_1-2,5枠_今節成績_2-1,5枠_今節成績_2-2,5枠_今節成績_3-1,5枠_今節成績_3-2,\
5枠_今節成績_4-1,5枠_今節成績_4-2,5枠_今節成績_5-1,5枠_今節成績_5-2,5枠_今節成績_6-1,5枠_今節成績_6-2,5枠_早見,\
6枠_艇番,6枠_登録番号,6枠_選手名,6枠_年齢,6枠_支部,6枠_体重,6枠_級別,\
6枠_全国勝率,6枠_全国2連対率,6枠_当地勝率,6枠_当地2連対率,\
6枠_モーター番号,6枠_モーター2連対率,6枠_ボート番号,6枠_ボート2連対率,\
6枠_今節成績_1-1,6枠_今節成績_1-2,6枠_今節成績_2-1,6枠_今節成績_2-2,6枠_今節成績_3-1,6枠_今節成績_3-2,\
6枠_今節成績_4-1,6枠_今節成績_4-2,6枠_今節成績_5-1,6枠_今節成績_5-2,6枠_今節成績_6-1,6枠_今節成績_6-2,6枠_早見\n"
# OSの機能を利用するパッケージ os をインポート
import os
# 正規表現をサポートするモジュール re をインポート
import re
# テキストファイルからデータを抽出し、CSVファイルに書き込む関数 get_data を定義
def get_data(text_file):
# CSVファイルを追記モードで開く
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "a", encoding="shift_jis")
# テキストファイルから中身を順に取り出す
for contents in text_file:
trans_asc = str.maketrans('1234567890R: ', '1234567890R: ')
# キーワード「番組表」を見つけたら(rは正規表現でraw文字列を指定するおまじない)
if re.search(r"番組表", contents):
# 1行スキップ
text_file.readline()
# タイトルを格納
line = text_file.readline()
title = line[:-1].strip()
# 1行スキップ
text_file.readline()
# 日次・レース日・レース場を格納
line = text_file.readline()
day = line[3:7].translate(trans_asc).replace(' ', '')
date = line[17:28].translate(trans_asc).replace(' ', '0')
stadium = line[52:55].replace(' ', '')
# キーワード「電話投票締切予定」を見つけたら
if re.search(r"電話投票締切予定", contents):
# キーワードを見つけた行を格納
line = contents
# レース名にキーワード「進入固定」が割り込んだ際の補正(「進入固定戦隊」は除くためHまで含めて置換)
if re.search(r"進入固定", line):
line = line.replace('進入固定 H', '進入固定 H')
# レース回・レース名・距離(m)・電話投票締切予定を格納
race_round = line[0:3].translate(trans_asc).replace(' ', '0')
race_name = line[5:21].replace(' ', '')
distance = line[22:26].translate(trans_asc)
post_time = line[37:42].translate(trans_asc)
# 4行スキップ(ヘッダー部分)
text_file.readline()
text_file.readline()
text_file.readline()
text_file.readline()
# 選手データを格納する変数を定義
racer_data = ""
# 選手データを読み込む行(開始行)を格納
line = text_file.readline()
# 空行またはキーワード「END」まで処理を繰り返す = 1~6艇分の選手データを取得
while line != "\n":
if re.search(r"END", line):
break
# 選手データを格納(行末にカンマが入らないように先頭にカンマを入れる)
racer_data += "," + line[0] + "," + line[2:6] + "," + line[6:10] + "," + line[10:12] \
+ "," + line[12:14] + "," + line[14:16] + "," + line[16:18] \
+ "," + line[19:23] + "," + line[24:29] + "," + line[30:34] \
+ "," + line[35:40] + "," + line[41:43] + "," + line[44:49] \
+ "," + line[50:52] + "," + line[53:58] + "," + line[59:60] \
+ "," + line[60:61] + "," + line[61:62] + "," + line[62:63] \
+ "," + line[63:64] + "," + line[64:65] + "," + line[65:66] \
+ "," + line[66:67] + "," + line[67:68] + "," + line[68:69] \
+ "," + line[69:70] + "," + line[70:71] + "," + line[71:73]
# 次の行を読み込む
line = text_file.readline()
# レースコードを生成
dict_stadium = {'桐生': 'KRY', '戸田': 'TDA', '江戸川': 'EDG', '平和島': 'HWJ',
'多摩川': 'TMG', '浜名湖': 'HMN', '蒲郡': 'GMG', '常滑': 'TKN',
'津': 'TSU', '三国': 'MKN', '琵琶湖': 'BWK', '住之江': 'SME',
'尼崎': 'AMG', '鳴門': 'NRT', '丸亀': 'MRG', '児島': 'KJM',
'宮島': 'MYJ', '徳山': 'TKY', '下関': 'SMS', '若松': 'WKM',
'芦屋': 'ASY', '福岡': 'FKO', '唐津': 'KRT', '大村': 'OMR'
}
race_code = date[0:4] + date[5:7] + date[8:10] + dict_stadium[stadium] + race_round[0:2]
# 抽出したデータをCSVファイルに書き込む
csv_file.write(race_code + "," + title + "," + day + "," + date + "," + stadium + "," + race_round
+ "," + race_name + "," + distance + "," + post_time + racer_data + "\n")
# CSVファイルを閉じる
csv_file.close()
# 開始合図
print("作業を開始します")
# CSVファイルを保存するフォルダを作成
os.makedirs(CSV_FILE_DIR, exist_ok=True)
# CSVファイルを作成しヘッダ情報を書き込む
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "w", encoding="shift_jis")
csv_file.write(CSV_FILE_HEADER)
csv_file.close()
# テキストファイルのリストを取得
text_file_list = os.listdir(TEXT_FILE_DIR)
# リストからファイル名を順に取り出す
for text_file_name in text_file_list:
# 拡張子が TXT のファイルに対してのみ実行
if re.search(".TXT", text_file_name):
# テキストファイルを開く
text_file = open(TEXT_FILE_DIR + text_file_name, "r", encoding="shift_jis")
# 関数 get_data にファイル(オブジェクト)を渡す
get_data(text_file)
# テキストファイルを閉じる
text_file.close()
print(CSV_FILE_DIR + CSV_FILE_NAME + " を作成しました")
# 終了合図
print("作業を終了しました")
うまくいけば、下図のように先頭の列にレースコードが挿入されます。
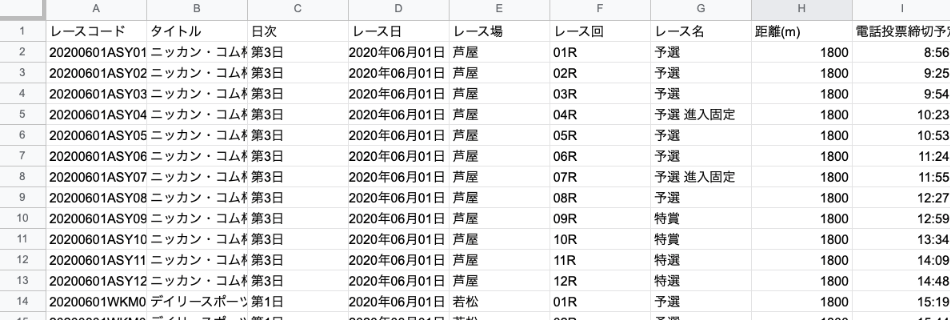
Pythonスクリプトの記述(競走成績)
最後に前回のシリーズで作成した競走成績のファイルでも、レースコードを出力できるように調整を加えましょう。ファイルの保存先、ヘッダー情報、レースコードの生成・出力などを加えました。
# 解凍したテキストファイルの格納先を指定
TEXT_FILE_DIR = "drive/My Drive/results_txt/"
# CSVファイルの保存先を指定
CSV_FILE_DIR = "drive/My Drive/results_csv_racecode/"
# CSVファイルの名前を指定 ※YYYYMMDDには対象期間を入力
CSV_FILE_NAME = "results_YYYYMMDD-YYYYMMDD.csv"
# CSVファイルのヘッダーを指定
CSV_FILE_HEADER = "レースコード,タイトル,日次,レース日,レース場,レース回,\
3連単_組番,3連単_払戻金,3連複_組番,3連複_払戻金,2連単_組番,2連単_払戻金,2連複_組番,2連複_払戻金\n"
# OSの機能を利用するパッケージ os をインポート
import os
# 正規表現をサポートするモジュール re をインポート
import re
# テキストファイルからデータを抽出し、CSVファイルに書き込む関数 get_data を定義
def get_data(text_file):
# CSVファイルを追記モードで開く
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "a", encoding="shift_jis")
# テキストファイルから中身を順に取り出す
for contents in text_file:
# キーワード「競争成績」を見つけたら(rは正規表現でraw文字列を指定するおまじない)
if re.search(r"競走成績", contents):
# 1行スキップ
text_file.readline()
# タイトルを格納
line = text_file.readline()
title = line[:-1].strip()
# 1行スキップ
text_file.readline()
# 日次・レース日・レース場を格納
line = text_file.readline()
day = line[3:7].replace(' ', '')
date = line[17:27].replace(' ', '0')
stadium = line[62:65].replace(' ', '')
# キーワード「払戻金」を見つけたら
if re.search(r"払戻金", contents):
# レース結果を読み込む行(開始行)を格納
line = text_file.readline()
# 空行まで処理を繰り返す = 1〜12レースまでの結果を取得
while line != "\n":
# レース結果を格納
results = line[10:13].replace(' ', '0') + "," \
+ line[15:20] + "," + line[21:28].strip() + "," \
+ line[32:37] + "," + line[38:45].strip() + "," \
+ line[49:52] + "," + line[53:60].strip() + "," \
+ line[64:67] + "," + line[68:75].strip()
# レースコードを生成
dict_stadium = {'桐生': 'KRY', '戸田': 'TDA', '江戸川': 'EDG', '平和島': 'HWJ',
'多摩川': 'TMG', '浜名湖': 'HMN', '蒲郡': 'GMG', '常滑': 'TKN',
'津': 'TSU', '三国': 'MKN', '琵琶湖': 'BWK', '住之江': 'SME',
'尼崎': 'AMG', '鳴門': 'NRT', '丸亀': 'MRG', '児島': 'KJM',
'宮島': 'MYJ', '徳山': 'TKY', '下関': 'SMS', '若松': 'WKM',
'芦屋': 'ASY', '福岡': 'FKO', '唐津': 'KRT', '大村': 'OMR'
}
race_round = line[10:12].replace(' ','0')
race_code = date[0:4] + date[5:7] + date[8:10] + dict_stadium[stadium] + race_round[0:2]
# 抽出したデータをCSVファイルに書き込む
csv_file.write(race_code + "," + title + "," + day + "," + date + "," + stadium + "," + results + "\n")
# 次の行を読み込む
line = text_file.readline()
# CSVファイルを閉じる
csv_file.close()
# 開始合図
print("作業を開始します")
# CSVファイルを格納するフォルダを作成
os.makedirs(CSV_FILE_DIR, exist_ok=True)
# CSVファイルを作成しヘッダ情報を書き込む
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "w", encoding="shift_jis")
csv_file.write(CSV_FILE_HEADER)
csv_file.close()
# テキストファイルのリストを取得
text_file_list = os.listdir(TEXT_FILE_DIR)
# リストからファイル名を順に取り出す
for text_file_name in text_file_list:
# 拡張子が TXT のファイルに対してのみ実行
if re.search(".TXT", text_file_name):
# テキストファイルを開く
text_file = open(TEXT_FILE_DIR + text_file_name, "r", encoding="shift_jis")
# 関数 get_data にファイル(オブジェクト)を渡す
get_data(text_file)
# テキストファイルを閉じる
text_file.close()
print(CSV_FILE_DIR + CSV_FILE_NAME + " を作成しました")
# 終了合図
print("作業を終了しました")
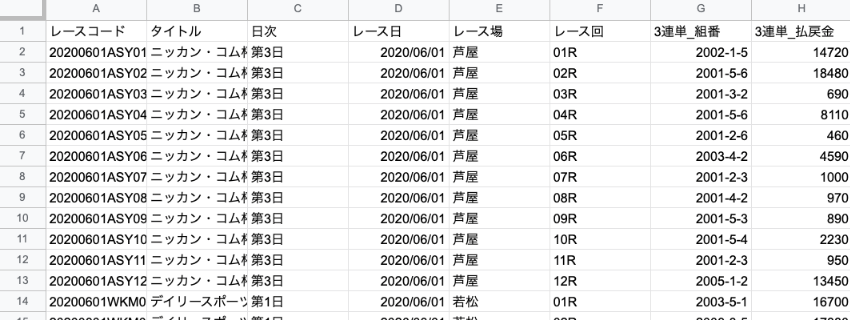
これで番組表と競走成績にレースコードを振ることができました。次回はこの2つのファイルを結合して分析してみましょう。

