

ダメ人間
オッズ! おらニート!
キョーコ、ニートだったの!!?
そこは「おー怖!!」って返さないとダメだよ〜。ニートにはなりたいけどね。
ボートレース好きのニートはダメ人間なので考え直して欲しい…
Webスクレイピングのポイント
さて、今回は実際にオッズデータを取得するスクリプトを紹介しますが、その前にWebスクレイピングのポイントを解説します。
PythonでWebスクレイピングを行うには、BeautifulSoupというモジュールを使います。
キョーコはPandasを使ってWebスクレイピングを行なっていましたが、Pandasは取得したデータをそのまま分析にかける場合に使います。Webサイトからデータを取得することを考えた場合、最初の選択肢としてはBeautifulSoupを使うことが一般的です。
まずは、getコマンドを使って指定したサイトからレスポンスを得ます。それをBeautifulSoupに渡して変数に格納します。
# BeautifulSoupにWebサイトのコンテンツを渡す
html = get(target_url)
soup = BeautifulSoup(html.content, 'html.parser')次に、css selectorを指定します。これはデータを取得する部分をタグの階層で示すもので、Chromeでは取得したいデータの上で右クリックし「検証」を選択します。
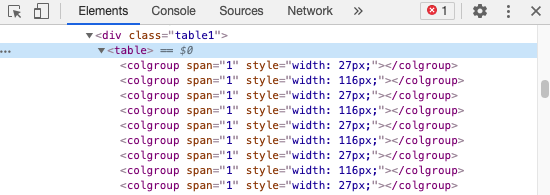
上図のようにHTMLの中身が表示されますので、取得したいtableタグの上で右クリックし「Copy」→「Copy Selector」を選んでください。そのタグの中身だけを変数に格納します。
なお、このcss selectorは3連単と2連単で同じでした。今回は2連単のオッズデータを取得しますが、3連単も同じ方法で取得することが可能ですので、次のステップとしていつかチャレンジしましょう。
# Webサイトからコピーしたcss selectorを貼り付け ※3連単と2連単は同じ
target_table_selector = \
"body > main > div > div > div > div.contentsFrame1_inner > div:nth-child(6) > table"
# css selectorで指定したHTMLタグの中身を取得
odds_table = soup.select_one(target_table_selector)レースが中止になった場合、レースコードがあるにもかかわらずオッズデータがない状態となります。それに備えて例外処理を入れます。
オッズデータがあった場合、table > tbody > trにオッズデータが格納されていますので、これをリスト形式で格納します。
# オッズデータがあった場合
try:
# tbodyを指定
odds_table_elements = odds_table.select_one("tbody")
# trを指定しリストとして格納
row_list = odds_table_elements.select("tr")ここまでがBeautifulSoupモジュールを用いたWebスクレイピングの流れになります。
スクリプトの記述
スクリプトの流れは前回紹介しましたが、もう一度おさらいしましょう。
- 競走成績または番組表のCSVファイルを用意
- CSVファイルの最初の列にあるレースコードを取得
- レースコードからレース場・レース回・レース日をデコード
- レース場・レース回・レース日と、指定した舟券種別でURLを生成
- URLからWebページを開き、オッズデータをスクレイピング
- オッズデータにレースコードを加えてCSVファイルに書き込む
このスクリプトの実行にはテイモンが考えたレースコードが必要です。レースコードについては以前のコラボでGOシリーズを参照してください。
なお、シリーズを重ねていく中でスクリプトも複雑化していますが、スクリプト中にコメントを多めに記載していますので、コラボで実行する前に一通り目を通しておくようにしましょう。それではどうぞ。
# レースコードが格納されているCSVファイルを指定 ※最初の列に格納されていること
RACECODE_FILE_PATH = \
"drive/My Drive/results_csv_racecode/results_YYYYMMDD-YYYYMMDD.csv"
# オッズデータを格納するCSVファイルの保存先を指定
ODDS_FILE_DIR = "drive/My Drive/odds_csv/"
# オッズデータを格納するCSVファイルの名前を指定
ODDS_FILE_NAME = "odds_YYYYMMDD-YYYYMMDD.csv"
# オッズデータを格納するCSVファイルのヘッダーを指定
ODDS_FILE_HEADER = "レースコード,\
2連単_1-2,2連単_2-1,2連単_3-1,2連単_4-1,2連単_5-1,2連単_6-1,\
2連単_1-3,2連単_2-3,2連単_3-2,2連単_4-2,2連単_5-2,2連単_6-2,\
2連単_1-4,2連単_2-4,2連単_3-4,2連単_4-3,2連単_5-3,2連単_6-3,\
2連単_1-5,2連単_2-5,2連単_3-5,2連単_4-5,2連単_5-4,2連単_6-4,\
2連単_1-6,2連単_2-6,2連単_3-6,2連単_4-6,2連単_5-6,2連単_6-5\n"
# URLの固定部分を指定
FIXED_URL = "https://www.boatrace.jp/owpc/pc/race/odds"
# 舟券種別を指定
BET_TYPE = "2tf"
# リクエスト間隔を指定(秒) ※サーバに負荷をかけないよう3秒以上を推奨
INTERVAL = 3
# HTMLからデータを取り出すモジュール BeautifulSoup をインポート
from bs4 import BeautifulSoup
# HTTP通信ライブラリの requests モジュールから get をインポート
from requests import get
# 時間を制御する time モジュールから sleep をインポート
from time import sleep
# OSの機能を利用するパッケージ os をインポート
import os
# CSVファイルの読み書きを行う csv モジュールをインポート
import csv
# Webサイトからオッズデータを抽出する関数 get_odds を定義
def get_odds(target_url):
# BeautifulSoupにWebサイトのコンテンツを渡す
html = get(target_url)
soup = BeautifulSoup(html.content, 'html.parser')
# Webサイトからコピーしたcss selectorを貼り付け ※3連単と2連単は同じ
target_table_selector = \
"body > main > div > div > div > div.contentsFrame1_inner > div:nth-child(6) > table"
# css selectorで指定したHTMLタグの中身を取得
odds_table = soup.select_one(target_table_selector)
# オッズデータがあった場合
try:
# tbodyを指定
odds_table_elements = odds_table.select_one("tbody")
# trを指定しリストとして格納
row_list = odds_table_elements.select("tr")
# オッズデータを格納する変数を定義
csv_row = []
# オッズデータを取得して変数に格納
for row in row_list:
for cell in row.select("td.oddsPoint"):
csv_row.append(cell.get_text())
# CSVデータを格納する変数を定義
csv_text = ""
# オッズデータにコロンを付けて変数に格納
for odds in csv_row:
csv_text += "," + odds
# オッズデータがなかった場合
except:
csv_text = "," + "No data"
return csv_text
# 開始合図
print("作業を開始します")
# オッズデータを格納するCSVファイルを保存するフォルダを作成
os.makedirs(ODDS_FILE_DIR, exist_ok=True)
# オッズデータを格納するCSVファイルを作成しヘッダ情報を書き込む
with open(ODDS_FILE_DIR + ODDS_FILE_NAME, "w", encoding="shift_jis") as csv_file:
csv_file.write(ODDS_FILE_HEADER)
# 先頭にwithを記載しているのでclose( )関数の処理は不要
# csv_file.close()
# レースコードを取得してURLを生成しオッズデータを取得
with open(RACECODE_FILE_PATH, "r", encoding="shift_jis") as race_code_file:
reader = csv.reader(race_code_file)
# ヘッダー行をスキップ
header = next(reader)
# レースコードを取得するCSVファイルを1行ずつ読み込む
for row in reader:
# 最初の列(レースコード)を格納
race_code = row[0]
# 3レターコードと場コードの対応表
dict_stadium = {'KRY': '01', 'TDA': '02', 'EDG': '03', 'HWJ': '04',
'TMG': '05', 'HMN': '06', 'GMG': '07', 'TKN': '08',
'TSU': '09', 'MKN': '10', 'BWK': '11', 'SME': '12',
'AMG': '13', 'NRT': '14', 'MRG': '15', 'KJM': '16',
'MYJ': '17', 'TKY': '18', 'SMS': '19', 'WKM': '20',
'ASY': '21', 'FKO': '22', 'KRT': '23', 'OMR': '24'
}
# レースコードからレース回・レース場(場コード)・レース日を取得
race_round = race_code[11:13]
stadium_code = dict_stadium[race_code[8:11]]
date = race_code[0:8]
# URLを生成
target_url = FIXED_URL + BET_TYPE + "?rno=" + race_round \
+ "&jcd=" + stadium_code + "&hd=" + date
print(target_url + " からオッズデータを取得します")
# 関数 get_odds にURLを渡しオッズデータを取得する
odds_data = get_odds(target_url)
# CSVファイルを追記モードで開き、レースコードとオッズデータを書き込む
with open(ODDS_FILE_DIR + ODDS_FILE_NAME, "a", encoding="shift_jis") as csv_file:
csv_file.write(row[0] + odds_data + "\n")
# 指定した間隔をあける
sleep(INTERVAL)
# 終了合図
print("作業を終了しました")分析例
オッズデータがあると何ができると思いますか?競走成績や番組表と結びつけることで、様々な検証ができそうですね。
例えば、1番人気に賭け続けた場合の回収率を計算することができます。この分析は「ココモ法」と呼ばれる掛け方のリスクを測るのに有益です。
ココモ法とは、負けたら賭け金を約2倍(前回と前々回の賭け金を足した金額)にして次のレースに賭けるという手法です。勝つことでそれまで累積した損失額を一気に回収できます。
ボートレースでは2.6倍以上のオッズであれば有効であるとされていますが、負けが続くと賭け金が膨れ上がります。100円からスタートして、10レース負け続けると損失額の累積が1万円を超え、15レース負け続けると損失額の累積は15万円を超え、さらに次のレースで10万円近く賭けなければなりません。
ただ、一度でも勝てばそれまでの損失額を回収できるので、10回に1回は勝てる手法を知っていれば賭け方としては有効かもしれません。
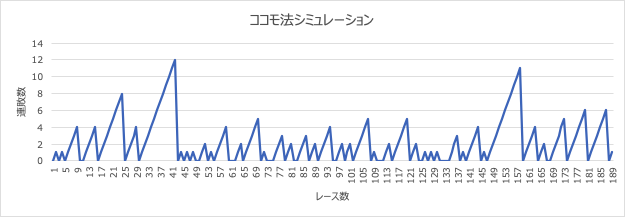
次のグラフは、テイモンがあるルールで賭け続けた場合、最大で何連敗するかをシミュレーションしたものです。縦軸が連敗数、横軸がレース数を示しています。
2連単の1番人気に掛けることとし、ただし1番人気が来にくいレースを様々な条件から外していった場合です。それでも最大で12回は連敗しますので冷や汗をかきそうですが、オッズデータがあることでこういった分析も可能になります。

