ずっとコラボでGO!(6)結果はどうなの?コンピューター予想
コンピューターおじいちゃん
私がコンピューターおばあちゃんになったら、テイモンはコンピューターおじいちゃんだね
キョーコ、コンピューターは人と違って年を取らないと思うよ
ふーん、じゃあテイモンは今でも5インチのフロッピーディスクから起動してるってこと?
せめて3.5インチにして欲しい…
コンピューター予想とは
ボートレースの公式サイトでは、レース毎に「コンピューター予想」を提供しています。公式が提供している予想ならさぞ当たるに違いない!? 実際はどうなのでしょうか。
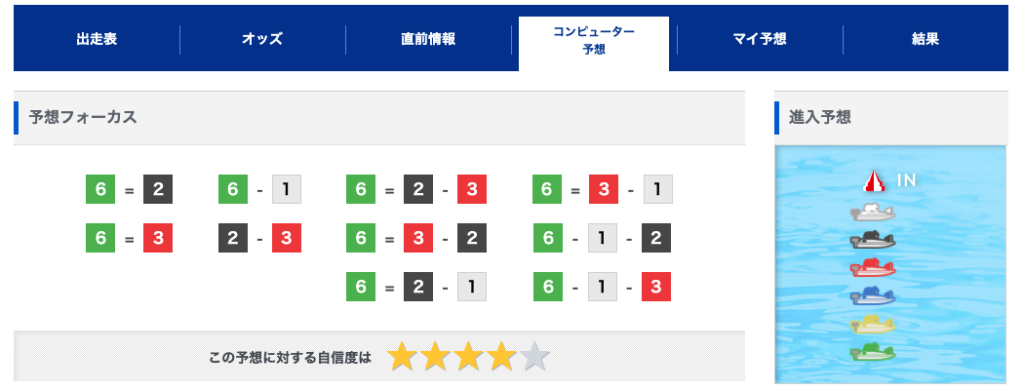
コンピューター予想のページを見ると、上部には「予想フォーカス」、「予想に対する自信度」、「進入予想」があり、下部にはレーサー毎に「印」といくつかのデータが並んでいます。
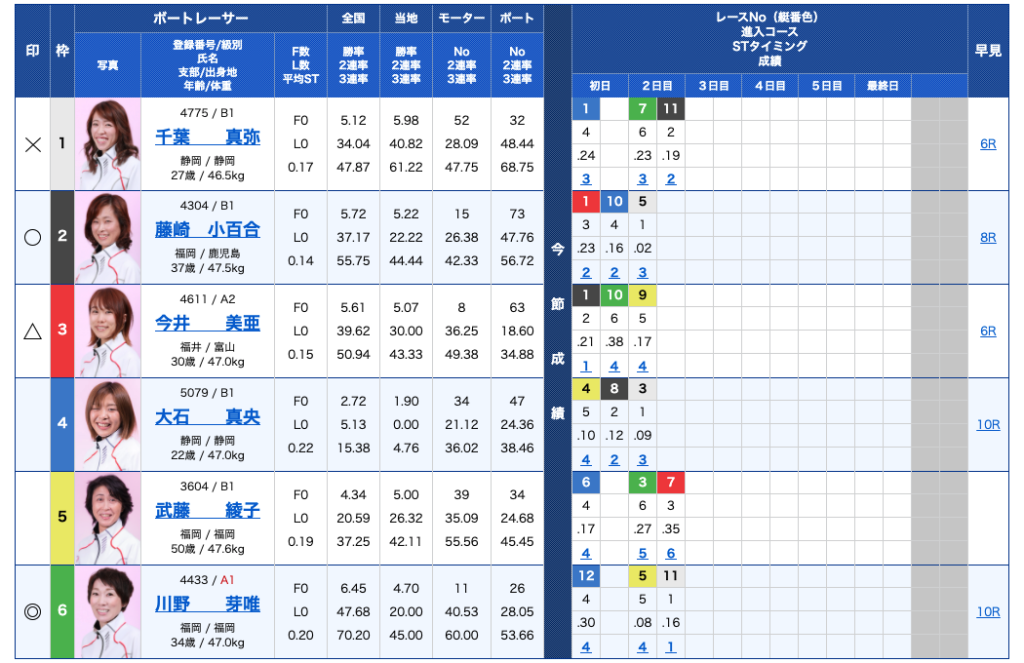
ここで注目して欲しいのは、予想フォーカスは「印」に沿って規則的に枠番が並んでいるに過ぎないということです。
予想フォーカスに4種類の印が入る位置は次の通りです。この組み合わせはどのレースにおいても同じようです。
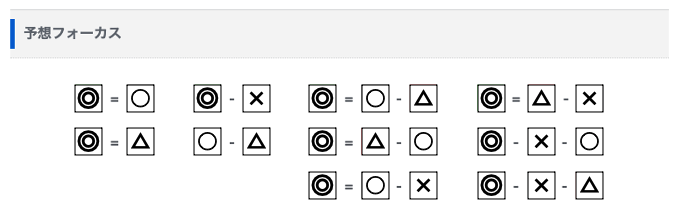
つまり、予想フォーカスは買い方(買い目)の提案であって、予想として見るべきは「印」だということになります。
予想印の意味
印は「予想印」と呼ばれ、競走対象(レーサーやモーターなど)の評価を記号化したものです。Wikipediaによると予想印は日本独特のもので、その歴史も古いそうです。
以下に予想印の種類や意味を整理しました。予想紙によっては▲や☆が使われることもありますが、ここではコンピューター予想で使われているものに絞ってまとめました。
| 予想印 | 名前 | 読み方 | 一般的な意味 |
| ◎ | 本命 | ほんめい | 1着になる可能性が高い。 |
| ◯ | 対抗 | たいこう | 本命の次に1着になる可能性が高い。 |
| △ | 単穴 | たんあな | 展開次第では本命・対抗を負かせるかもしれない。 |
| × | 連下 | れんした | レースに勝つのは難しいが、2着以内に入る可能性がある。 |
| 無印 | 問題外 | もんだいがい | 評価なし |
公式サイトがこれらの印をどのような基準で付けているのか興味津々ですが、ここではコンピューター予想が当たるのかどうかにフォーカスして話を進めることにします。
前回学んだWebスクレイピングを利用して、レース毎に予想印を取得してみましょう。
スクリプトの記述
スクリプトの流れは前回と同じです。Webスクレイピングで取得したい予想印は画像ファイルですので、画像そのものを取り出すのではなくファイル名を取得することを考えます。
まず、今回はcss selectorを2段階で用いています。他に方法があるかもしれませんが、2段階で入れることで予想印の列のタグだけを抽出できます。
# BeautifulSoupにWebサイトのコンテンツを渡す
html = get(target_url)
soup = BeautifulSoup(html.content, 'html.parser')
# css selectorで表とセルを指定する
selector_1 = "body > main > div > div > div > div.contentsFrame1_inner > div:nth-child(5) > table"
selector_2 = "tbody:nth-of-type(1) > tr:nth-of-type(1) > td:nth-of-type(1)"
try:
# 表の中身を取得
mark_table = soup.select_one(selector_1)
# セルの中身を取得 ※1〜6枠分をリスト形式で取得
mark_cell = mark_table.select(selector_2)次に、予想印の画像ファイル名を検索して、そのファイル名の一部分(予想印を指定している部分)を抜き出します。予想印がない場合も0を入れておきます。
for mark in mark_cell:
# 予想印の画像ファイル名「icon_mark1_n」を検索
if re.search(r"icon_mark1_", str(mark)):
# ファイル名から予想印の種類を指定している部分を格納
mark_list.append(str(mark)[81:82])
else:
mark_list.append("0")なお、このスクリプトを実行するにはテイモンが考えたレースコードが必要ですので、競走成績や番組表を取得していない場合は以前のコラボでGOシリーズを参照してください。
それでは次のスクリプトをコラボにコピペして実行してみましょう。
# レースコードが格納されているCSVファイルを指定 ※最初の列に格納されていること
RACECODE_FILE_PATH = \
"drive/My Drive/results_csv_racecode/results_YYYYMMDD-YYYYMMDD.csv"
# 予想データを格納するCSVファイルの保存先を指定
MARK_FILE_DIR = "drive/My Drive/mark_csv/"
# 予想データを格納するCSVファイルの名前を指定
MARK_FILE_NAME = "mark_YYYYMMDD-YYYYMMDD.csv"
# オッズデータを格納するCSVファイルのヘッダーを指定
MARK_FILE_HEADER = \
"レースコード,1枠_予想印,2枠_予想印,3枠_予想印,4枠_予想印,5枠_予想印,6枠_予想印\n"
# URLの固定部分を指定
FIXED_URL = "https://www.boatrace.jp/owpc/pc/race/pcexpect"
# リクエスト間隔を指定(秒) ※サーバに負荷をかけないよう3秒以上を推奨
INTERVAL = 1
# HTMLからデータを取り出すモジュール BeautifulSoup をインポート
from bs4 import BeautifulSoup
# HTTP通信ライブラリの requests モジュールから get をインポート
from requests import get
# 時間を制御する time モジュールから sleep をインポート
from time import sleep
# OSの機能を利用するパッケージ os をインポート
import os
# CSVファイルの読み書きを行う csv モジュールをインポート
import csv
# 正規表現をサポートするモジュール re をインポート
import re
# Webサイトから予想データを抽出する関数 get_mark を定義
def get_mark(target_url):
# BeautifulSoupにWebサイトのコンテンツを渡す
html = get(target_url)
soup = BeautifulSoup(html.content, 'html.parser')
# css selectorで表とセルを指定する
selector_1 = "body > main > div > div > div > div.contentsFrame1_inner > div:nth-child(5) > table"
selector_2 = "tbody:nth-of-type(1) > tr:nth-of-type(1) > td:nth-of-type(1)"
try:
# 表の中身を取得
mark_table = soup.select_one(selector_1)
# セルの中身を取得 ※1〜6枠分をリスト形式で取得
mark_cell = mark_table.select(selector_2)
# 予想印を格納する変数を定義
mark_list = []
for mark in mark_cell:
# 予想印の画像ファイル名「icon_mark1_n」を検索
if re.search(r"icon_mark1_", str(mark)):
# ファイル名から予想印の種類を指定している部分を格納
mark_list.append(str(mark)[81:82])
else:
mark_list.append("0")
# CSVデータを格納する変数を定義
csv_text = ""
# 予想データにコロンを付けて変数に格納
for mark in mark_list:
csv_text += "," + mark
# 予想データがなかった場合
except:
csv_text = "," + "No data"
return csv_text
# 開始合図
print("作業を開始します")
# 予想データを格納するCSVファイルを保存するフォルダを作成
os.makedirs(MARK_FILE_DIR, exist_ok=True)
# 予想データを格納するCSVファイルを作成しヘッダ情報を書き込む
with open(MARK_FILE_DIR + MARK_FILE_NAME, "w", encoding="shift_jis") as csv_file:
csv_file.write(MARK_FILE_HEADER)
# レースコードを取得してURLを生成し予想データを取得
with open(RACECODE_FILE_PATH, "r", encoding="shift_jis") as race_code_file:
reader = csv.reader(race_code_file)
# ヘッダー行をスキップ
header = next(reader)
# レースコードを取得するCSVファイルを1行ずつ読み込む
for row in reader:
# 最初の列(レースコード)を格納
race_code = row[0]
# 3レターコードと場コードの対応表
dict_stadium = {'KRY': '01', 'TDA': '02', 'EDG': '03', 'HWJ': '04',
'TMG': '05', 'HMN': '06', 'GMG': '07', 'TKN': '08',
'TSU': '09', 'MKN': '10', 'BWK': '11', 'SME': '12',
'AMG': '13', 'NRT': '14', 'MRG': '15', 'KJM': '16',
'MYJ': '17', 'TKY': '18', 'SMS': '19', 'WKM': '20',
'ASY': '21', 'FKO': '22', 'KRT': '23', 'OMR': '24'
}
# レースコードからレース回・レース場(場コード)・レース日を取得
race_round = race_code[11:13]
stadium_code = dict_stadium[race_code[8:11]]
date = race_code[0:8]
# URLを生成
target_url = FIXED_URL + "?rno=" + race_round \
+ "&jcd=" + stadium_code + "&hd=" + date
print(target_url + " から予想データを取得します")
# 関数 get_mark にURLを渡し予想データを取得する
mark_data = get_mark(target_url)
# CSVファイルを追記モードで開き、レースコードとオッズデータを書き込む
with open(MARK_FILE_DIR + MARK_FILE_NAME, "a", encoding="shift_jis") as csv_file:
csv_file.write(row[0] + mark_data + "\n")
# 指定した間隔をあける
sleep(INTERVAL)
# 終了合図
print("作業を終了しました")分析例
うまく取得できていれば、下図のようなCSVファイルになっているはずです。
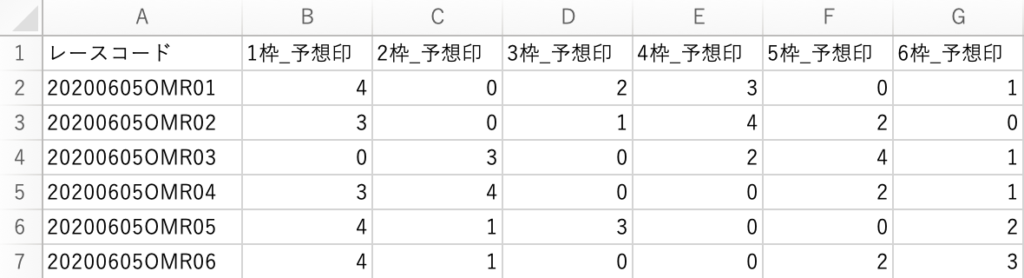
数字は予想印の画像ファイルの番号を示しています。対応は次の通りです。3が×で4が△であることに注意してください。
| 予想印 | 名前 | 読み方 | 一般的な意味 | 画像ファイル# |
| ◎ | 本命 | ほんめい | 1着になる可能性が高い。 | 1 |
| ◯ | 対抗 | たいこう | 本命の次に1着になる可能性が高い。 | 2 |
| △ | 単穴 | たんあな | 展開次第では本命・対抗を負かせるかもしれない。 | 4 |
| × | 連下 | れんした | レースに勝つのは難しいが、2着以内に入る可能性がある。 | 3 |
| 無印 | 問題外 | もんだいがい | 評価なし | 0 |
分析例では、単純に本命と対抗に絞って勝率と回収率を見てみましょう。つまり、◎ー◯と◯ー◎を2連単で購入した場合を考えます。結果は次の通りでした。
| 期間 | 2020年6月1日〜6日 |
| レース数 | n=936 |
| レース毎の賭け金 | 200円 ◎ー◯と◯ー◎ |
| 勝ち数 | 177 |
| 負け数 | 759 |
| 勝率 | 18.91 % |
| 賭け金の合計 | 187,200円 |
| 払戻金の合計 | 116,610円 |
| 回収率 | 62.29 % |
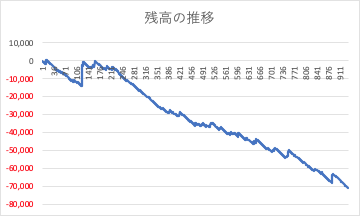
結論としてはボロ負けですね。。。ただ、勝てないと結論づけるのは早計です。
今回はデータを取得しませんでしたが、コンピューター予想には「自信度」という指標があり、自信の高いレースだけに賭ける分析もできると思います。また、買い目を変えることで別の結果が出てくるかもしれません。
Webスクレイピングしたデータを使えば分析の幅が広がっていきます。この先も様々な分析にチャレンジしてみましょう。