COBOLおじさん
前の章で解凍した競争成績のファイルをGoogleドライブでプレビューしてみましょう。
Google Colaboratoryの左上にあるアイコンをクリックすると(なぜか)Googleドライブに飛びますので、左のメニューから「マイドライブ」→「results_txt」フォルダをクリックして解凍したファイルをダブルクリックしてください。
すると、ドンッ!

開けてびっくり玉手箱!! これを使ってどうやって分析しろと!?
ボートレース(競艇)の公式サイトからデータをダウンロードして、ファイルを解凍してみた人は多いと思います。しかし、ほとんどの人はこのファイルを開いて分析諦めたのではないでしょうか。
これは固定長ファイルと言って、長さが決まっているデータの集まりです。文字や数字がきれいに並んでいますが、ここから欲しいデータを抜き出すには工夫が必要です。
余談ですが、IT系の人であればこのファイルが汎用機から出力されていること、COBOLで書かれていること、それをメンテするおじさんがいることなどをイメージできますね!(注: すべてテイモンの勝手な想像です)
区切り位置指定ウィザードは使えるか?
ところで、Excelには伝家の宝刀「区切り位置指定ウィザード」という機能があります。固定長データであれば、区切り位置を指定してセルに分割しようとかんがこれを利用してテキストファイルをセルに分割しようと考えた人がいるかもしれません。
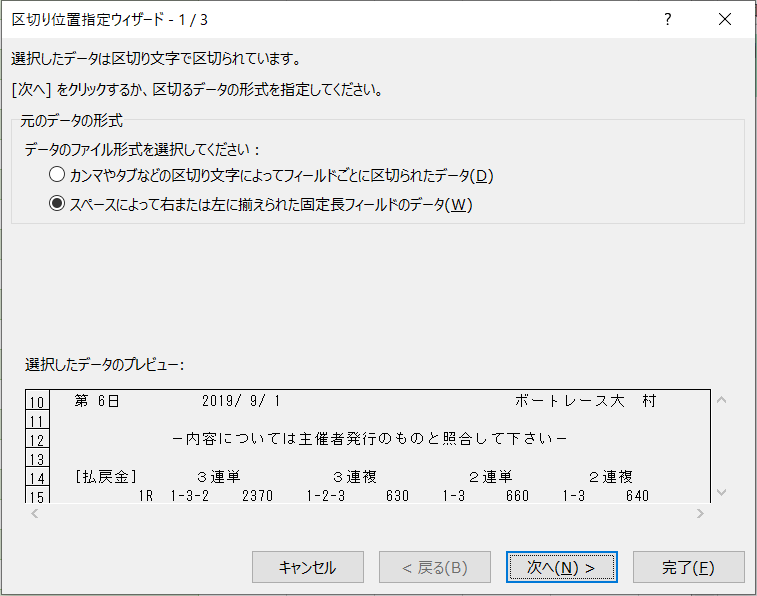
このウィザードは、フィールド(列のデータ)の長さが揃っているときや、区切り文字が決まっているときには有効です。しかし、競争成績のテキストファイルは途中の行に開催日やレース場などが入り込んでいるため、すぐに不向きだと分かりますね。
そこで、ここでは別の方法でデータを抜き出すことを考えてみましょう。
まずはじっくり観察しよう
競争成績のテキストファイルをじっくり観察してみると、以下のような特徴が見えてきます。
- 最初と最後の行に特定のキーワードがある
最初の行 →STARTK
最後の行 →FINALK - レース場ごとに競争結果がまとめられ、その最初と最後の行に特定のキーワードがある
最初の行 →[場コード] + KBGN
最後の行 →[場コード] + KEND - レース場ごとの競争結果は、まず概要があり、次にレース回ごとの詳細がある
- 結果の概要は「競争成績」と書かれた行から始まっている
- 結果の詳細は「レース回」「レース名」「距離」などのヘッダーから始まっている
別の日の競争結果のファイルを見ても、必ず上記の構成になっています。
決められたルールに従ってデータが格納されているとして、そのファイルからデータを抜き出そうと考えた場合、大きく分けて2種類の方法が考えられます。
- 絶対位置の指定 →先頭から何行目・何文字目かを指定して抽出
- 相対位置の指定 →キーワードから何行目・何文字目かを指定して抽出
絶対位置を指定するには、ファイルによってデータの位置が変わらないことが条件になりますが、競争成績のテキストファイルは中止や同着などにより、データの位置が変わることが分かっています。
そこで、キーワードをから相対的な位置を指定してデータを抜き出すことを考えてみましょう。
取得したいデータは何か?
ある日、キョーコは1-2-3の3連単ボックスは当たりやすいのではないかと考え、1-2-3の3連単ボックスが来やすいレース場やレース回を調べることにしました。
競争成績のテキストファイルから以下のデータを抜き出せば調べられそうです。
- レース場
- レース回
- 3連単_払戻金
- 3連複_組番 ←3連単ボックスの勝敗を判定するために利用
ここでは先のことも考えて、以下の情報をまとめて抜き出すことにします。
- タイトル
- 日次
- レース日
- レース場
- レース回
- 3連単_組番
- 3連単_払戻金
- 3連複_組番
- 3連複_払戻金
- 2連単_組番
- 2連単_払戻金
- 2連複_組番
- 2連複_払戻金
競争成績のテキストファイルを確認すると、キョーコが知りたいデータは競争成績の概要に含まれていることが分かります。
取得したいデータの相対的な位置を指定するためには、それらのデータに近い場所に必ず含まれるキーワードを見つける必要があります。どうやら「競争成績」と「払戻金」が使えそうです。
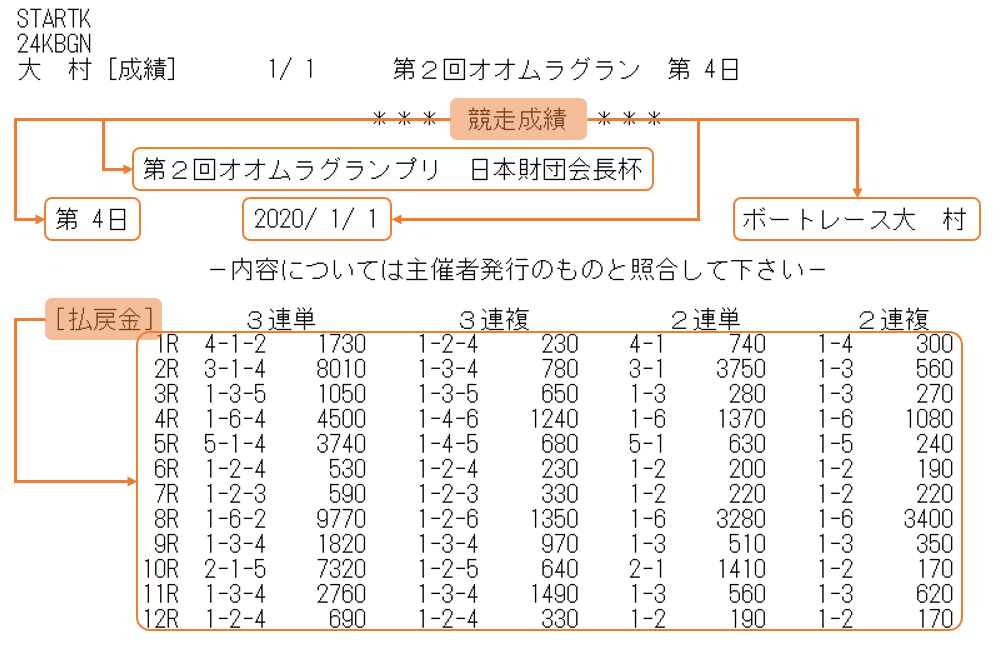
それでは「競争成績」と「払戻金」をキーワードにして、そこからキョーコが知りたい情報の相対的な位置を考えて、実際にデータを抜き出してみましょう。
スクリプトの流れを理解しよう
まずは、どのようなスクリプトを書けば目的のデータを作れるか考えてみましょう。
- 競争成績のテキストファイルを開く
- ファイルの内容を1行ずつチェック
- キーワード「競争成績」が見つかったら、その下にある「タイトル」「日次」「レース日」「レース場」の情報を取得
- キーワード「払戻金」が見つかったら、その下にある「レース回」「3連単_組番」「3連単払戻金」などの情報を取得
- CSVファイルに取得したデータを書き込む
- テキストファイルを閉じて次のファイルを開く
それでは上記の流れプログラムを組んでみましょう。これができると応用範囲が広がりますので、ぜひマスターしてください。
例によって、初心者の人はコラボで作成したノートブックのセルに以下のスクリプトを丸っとコピーし
て実行するだけです。
ただ、もし可能であればスクリプトの内容を読んでみてください。初心者の人にも分かりやすいように、どこで何をしているのかコメントしてありますので、これを機にプログラミングに興味を持っていただけると嬉しいです。
# テキストファイルが保存されている場所を指定
TXT_FILE_DIR = "drive/My Drive/results_txt/"
# CSVファイルを保存する場所を指定
CSV_FILE_DIR = "drive/My Drive/results_csv/"
# CSVファイルの名前を指定
CSV_FILE_NAME = "results.csv"
# CSVファイルのヘッダ情報を指定
CSV_FILE_HEADER = "タイトル,日次,レース日,レース場,レース回,\
3連単_組番,3連単_払戻金,3連複_組番,3連複_払戻金,2連単_組番,2連単_払戻金,2連複_組番,2連複_払戻金\n"
# 正規表現をサポートするモジュール re をインポート
import re
# オペレーティングシステムの機能を利用するパッケージ os をインポート
import os
# 開始合図
print("作業を開始します")
# CSVファイルを格納するフォルダを作成
os.makedirs(CSV_FILE_DIR, exist_ok=True)
# CSVファイルを作成しヘッダ情報を書き込む
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "w", encoding="shift_jis")
csv_file.write(CSV_FILE_HEADER)
csv_file.close()
# テキストファイルからデータを抽出し、CSVファイルに書き込む関数
def get_data(text_file):
# CSVファイルを追記モードで開く
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "a", encoding="shift_jis")
# テキストファイルからデータを抽出
for contents in text_file:
# 文字列「競争成績」を検索してタイトル・日次・レース日・レース場を取得
# rは正規表現でraw文字列を指定するおまじない
if re.search(r"競走成績", contents):
# 1行スキップ
text_file.readline()
# タイトルを取得
line = text_file.readline()
title = line[:-1].strip()
# 1行スキップ
text_file.readline()
# 日次、レース日、レース場を取得
line = text_file.readline()
day = line[3:7].replace(' ', '')
date = line[17:27].replace(' ', '')
stadium = line[62:65].replace(' ', '')
# 文字列「払戻金」を検索してレース結果を取得
if re.search(r"払戻金", contents):
line = text_file.readline()
# 空行まで処理を繰り返す = 12レース分を取得
while line != "\n":
results = line[10:13].strip() + "," \
+ line[15:20] + "," + line[21:28].strip() + "," \
+ line[32:37] + "," + line[38:45].strip() + "," \
+ line[49:52] + "," + line[53:60].strip() + "," \
+ line[64:67] + "," + line[68:75].strip()
# 抽出したデータをCSVファイルに書き込む
csv_file.write(title + "," + day + "," + date + "," + stadium + "," + results + "\n")
# 次の行を読み込む
line = text_file.readline()
# CSVファイルを閉じる
csv_file.close()
# テキストファイルのリストを取得
text_file_list = os.listdir(TXT_FILE_DIR)
# ファイルの数だけ処理を繰り返す
for txt_file_name in text_file_list:
# 拡張子が txt のファイルに対してのみ実行
if re.search(".TXT", txt_file_name):
# テキストファイルを開く
text_file = open(TXT_FILE_DIR + txt_file_name, "r", encoding="shift_jis")
# データを抽出する
get_data(text_file)
# テキストファイルを閉じる
text_file.close()
print(CSV_FILE_DIR + CSV_FILE_NAME + " を作成しました")
# 終了合図
print("作業を終了しました")
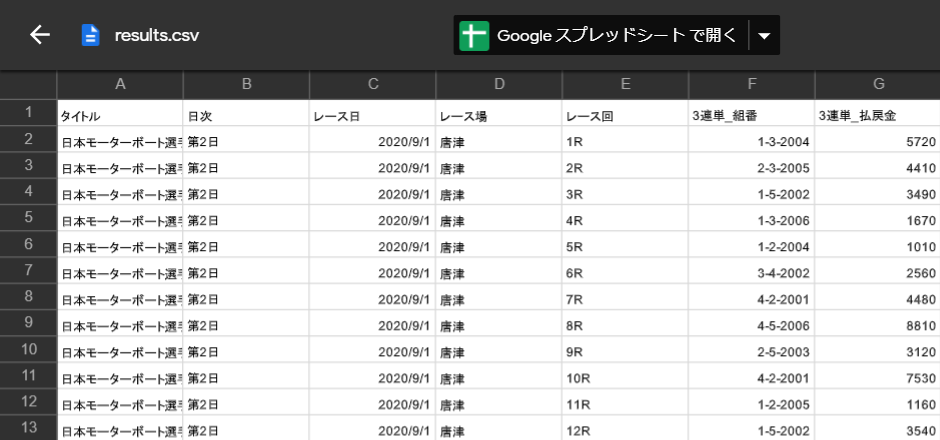
無事に実行できれば、以下のようにCSVファイルが作成されます。
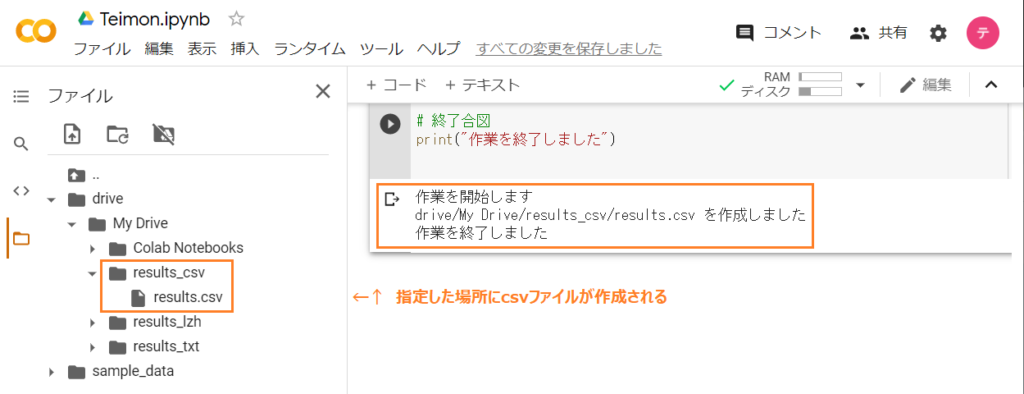
また、Googleドライブから作成したファイルをプレビューすると、抽出したデータが格納されていることが分かります。
しかし、3連単_組番を見てみるとデータが変ですね。これはGoogle スプレッドシートがF列を自動で日付型として認識しているために発生します。
次の章では、Google スプレッドシートでCSVファイルを正しく読み込む方法を説明します。