もっとコラボでGO!(2)実はほぼ一緒!?番組表と競争成績の取得

チャンネルはテレ東に!?
ボートレースの番組表なんてあるの?知らなかったー
そりゃあるよ。番組表がないと明日の組み合わせだって分からないし、ないと困るじゃん?
そっか!好きな選手が出るレースは録画しときたいもんね。ちなみに明日の毒島選手が出るレースってなんチャン?12チャンだと予約が被ったら嫌だなー
キョーコ、なんかいろいろ違う。。。
番組表とは何ぞや
ボートレースで番組表と言えば、もちろん「出走表」のことです。番組表を見れば、いつ・どこで・誰が・誰と・何のレースに出場するのか分かります。
また、番組表には出走するレーサーやモーターなどに関するデータも記載されているため、予想には欠かせない存在です。例えば、レーサーの年齢や体重、勝率や2連対率(2着以内に入る確率)、前日までの結果などがそうです。
番組表と競走結果のデータを紐づけることで、番組表にある指標が競走結果にどのくらい影響するか調べることができるようになります。分析の裏付けには統計の知識が必要になりますが、これはまた別の機会にご説明します。
余談ですが、番組の構成(レーサーの組み合わせ)を決める人を「番組マン」と呼ぶそうです。レースを盛り上げるために最適な組み合わせを考えてくれる人たちがいるんですね。
ダウンロードできる場所
前回のシリーズ『コラボでGO!(3)』では、ボートレースの公式サイトから競争成績をダウンロードしました。Pythonを使って、指定した期間の競争成績を自動でダウンロードしましたね。
番組表も競争成績と同じ方法でダウンロードすることができます。
ボートレースの公式サイトから「データを調べる」→「ダウンロード・他」をクリックし、下段の各種ダウンロードにある「番組表ダウンロード」を選択してください。
するとドンッ!

出ました築古サイト(笑) なんだかアングラな香りも漂いますね。。。
番組表もインターネットの黎明期から提供されていたと考えると歴史を感じます。ひょっとしたらパソコン通信の時代からあったのかな? 少なくともファンページはあったと思います。
ここでも競走成績のページと同じようにフレームが使われています。上段のページで年月を選択すると、下段のページに年月に対応した日付ページが表示される仕組みです。
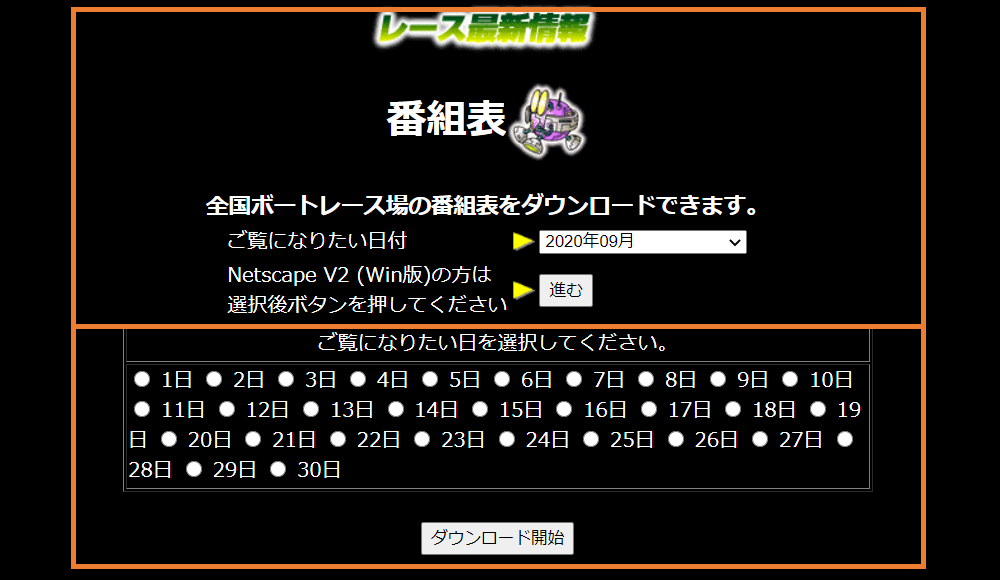
ここで日付を選択して「ダウンロード開始」ボタンを押すとダウンロードが始まりますが、これを永遠と続けるのは非効率なので自動化を検討しましょう。
コラボでGO!シリーズは、すべてGoogleのプラットフォーム上で完結させることを目標にしています。
ファイルのURLを取得
「ダウンロード開始」ボタンの近くでマウスを右クリックし、メニューから「フレームのソースを表示」を選択してください。
ソースの上部にJava Scriptが記載されていますが、ここでURLを生成しています。
テイモンがコメントとインデントを入れて見やすくしているので、一緒にスクリプトをチェックしましょう。
<SCRIPT LANGUAGE="JavaScript">
<!--
// 変数dirにベースとなるURLを代入。location.hostはドメイン名
var dir="http://"+location.host+"/od2/B/202009/b2009";
// ダウンロード開始ボタンを押下したときに実行される関数
function download(t){
var i;
var m;
// 日にちが選択されていない場合
if( t.form.MDAY.length==null){
m = t.form.MDAY.value;
}
// 日にちが選択されている場合
else{
for(i = 0; i < t.form.MDAY.length; i++){
if(t.form.MDAY[i].checked){
// 変数mに選択された日付のvalue(2桁の日付)を代入
m = t.form.MDAY[i].value;
break;
}
}
}
// 変数locationにダウンロードするファイルのURLを代入
location= dir + m + ".lzh";
}
//-->
</SCRIPT>競争成績のページと比較すると、変数の取り方に若干の違いがあるものの、ほぼ同じスクリプトです。ドメイン名は www1.mbrace.or.jp ですから、ここから生成されるURLは次の通りです。
http://www1.mbrace.or.jp/od2/B/202009/b2009 + 2桁の日付 + .lzh
年月の部分はフレームの上部で選択した年月によって変わりますので、ダウンロードするファイルのURLのルールは次のようになります。
http://www1.mbrace.or.jp/od2/B/YYYYMM/bYYMMDD.lzh
YYYY: 西暦4桁
YY: 西暦下2桁
MM: 月2桁
DD: 日2桁
前回のシリーズで競争成績をダウンロードした人ならもうお分かりですね! 番組表と競走成績のURLは、B(b)とK(k)が違うだけでほとんど一緒です。
Pythonスクリプトの記述
それでは番組表のダウンロードから解凍までを一気にやってしまいましょう。
前回のシリーズ『コラボでGO!(3)・(4)』で紹介したスクリプトとほとんど同じです。違いは以下の部分だけになります。
| # | 違いのある場所 | 競争成績 | 番組表 |
| 1 | URLの固定部分 | http://www1.mbrace.or.jp/od2/K/ | http://www1.mbrace.or.jp/od2/B/ |
| 2 | ファイル名 | k + yymmdd + .lzh | b + yymmdd + .lzh |
| 3 | 保存先(任意) | drive/My Drive/results_lzh/ | drive/My Drive/timetable_lzh/ |
| 4 | 解凍先(任意) | drive/My Drive/results_txt/ | drive/My Drive/timetable_txt/ |
#1、#3、#4は、スクリプトの上部で定数として設定しているので、その部分を書き換えるだけです。
#2はハードコーディングしているため該当部分を書き換える必要がありますが、スクリプトの上部にないだけで定数と同じように変更するだけです。2ヶ所あるのでそこだけ注意しましょう。
番組表をダウンロードするスクリプトは次の通りです。競争成績をダウンロードするスクリプトからコピーする場合は、上の表を参考に必要な箇所を変更して利用しましょう。
# 開始日と終了日を指定(YYYY-MM-DD)
START_DATE = "2020-06-01"
END_DATE = "2020-06-07"
# ファイルの保存先を指定 ※コラボでGoogleドライブをマウントした状態を想定
SAVE_DIR = "drive/My Drive/timetable_lzh/"
# リクエスト間隔を指定(秒) ※サーバに負荷をかけないよう3秒以上を推奨
INTERVAL = 3
# URLの固定部分を指定
FIXED_URL = "http://www1.mbrace.or.jp/od2/B/"
# 日付を扱う datetime モジュールから datetime と timedelta をインポート
from datetime import datetime as dt
from datetime import timedelta as td
# HTTP通信ライブラリの requests モジュールから get をインポート
from requests import get
# OSの機能を利用する os モジュールから makedirs をインポート
from os import makedirs
# 時間を制御する time モジュールから sleep をインポート
from time import sleep
# 開始合図
print("作業を開始します")
# ファイルを保存するフォルダを作成
makedirs(SAVE_DIR, exist_ok=True)
# 開始日と終了日を日付型に変換して格納
start_date = dt.strptime(START_DATE, '%Y-%m-%d')
end_date = dt.strptime(END_DATE, '%Y-%m-%d')
# 日付の差から期間を計算
days_num = (end_date - start_date).days + 1
# 日付リストを格納する変数を定義
date_list = []
# 期間から日付を順に取り出す
for d in range(days_num):
# 開始日からの日付に変換
target_date = start_date + td(days=d)
# 日付(型)を文字列に変換してリストに格納(YYYYMMDD)
date_list.append(target_date.strftime("%Y%m%d"))
# 日付リストから日付を順に取り出す
for date in date_list:
# URL用に日付の文字列を生成
yyyymm = date[0:4] + date[4:6]
yymmdd = date[2:4] + date[4:6] + date[6:8]
# URLとファイル名を生成
variable_url = FIXED_URL + yyyymm + "/b" + yymmdd + ".lzh"
file_name = "b" + yymmdd + ".lzh"
# 生成したURLでファイルをダウンロード
r = get(variable_url)
# 成功した場合
if r.status_code == 200:
# ファイル名を指定して保存
f = open(SAVE_DIR + file_name, 'wb')
f.write(r.content)
f.close()
print(variable_url + " をダウンロードしました")
# 失敗した場合
else:
print(variable_url + " のダウンロードに失敗しました")
# 指定した間隔をあける
sleep(INTERVAL)
# 終了合図
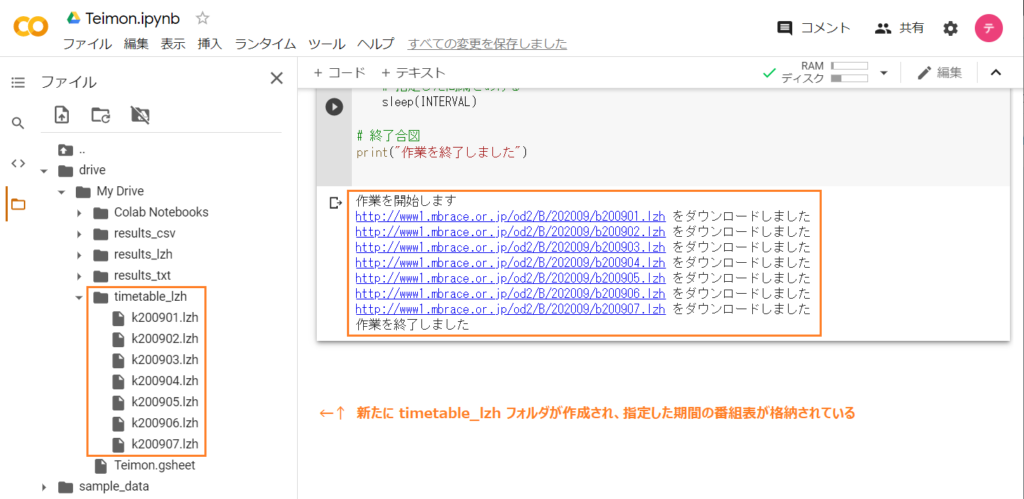
print("作業を終了しました")正常にダウンロードできれば下図のようになります。
ファイルの解凍
続けてダウンロードしたファイルを解凍しましょう。
『コラボでGO!(4)』のスクリプトを使います。解凍前のファイルが入っている格納先と解凍先のフォルダのみ変更してください。
# ダウンロードしたLZHファイルの格納先を指定
LZH_FILE_DIR = "drive/My Drive/timetable_lzh/"
# ファイルの解凍先を指定
TEXT_FILE_DIR = "drive/My Drive/timetable_txt/"
# LZH形式のファイルを解凍するパッケージ lhafile をインポート
import lhafile
# OSの機能を利用するパッケージ os をインポート
import os
# 正規表現をサポートするモジュール re をインポート
import re
# 開始合図
print("作業を開始します")
# ファイルを保存するフォルダを作成
os.makedirs(TEXT_FILE_DIR, exist_ok=True)
# LZHファイルのリストを取得
lzh_file_list = os.listdir(LZH_FILE_DIR)
# リストからファイル名を順に取り出す
for lzh_file_name in lzh_file_list:
# 拡張子が lzh のファイルに対してのみ実行
if re.search(".lzh", lzh_file_name):
# LZHファイルを解凍
file = lhafile.Lhafile(LZH_FILE_DIR + lzh_file_name)
# 解凍したファイルの名前を取得
info = file.infolist()
file_name = info[0].filename
# ファイル名を指定して保存
f = open(TEXT_FILE_DIR + file_name, 'wb')
f.write(file.read(file_name))
f.close()
print(TEXT_FILE_DIR + lzh_file_name + " を解凍しました")
# 終了合図
print("作業を終了しました")しかし! このまま実行すると下図のように失敗することがあります。なぜでしょうか?
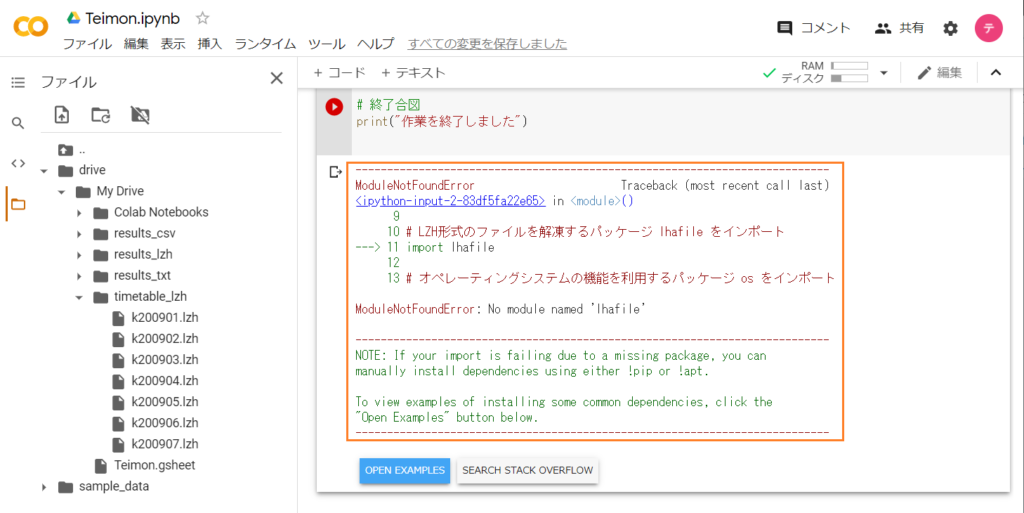
察しのいい人はスクリプトを実行する前に「ちょっと待ったぁぁあ」となったはず!
そうです。pipコマンドを実行しないといけません。上図のエラーをよく見てみると「ModuleNotFoundError: No module named 'lhafile'」と書かれていますね。これはlhafileモジュールが見つかりませんという意味です。
『コラボでGO!(4)』で実行したpipコマンドは、環境が初期化されると効力を失う(インストールしたモジュールは削除される)ので再度実行する必要があります。スクリプトを実行する前にpipコマンドでlhafileモジュールをインストールしましょう。
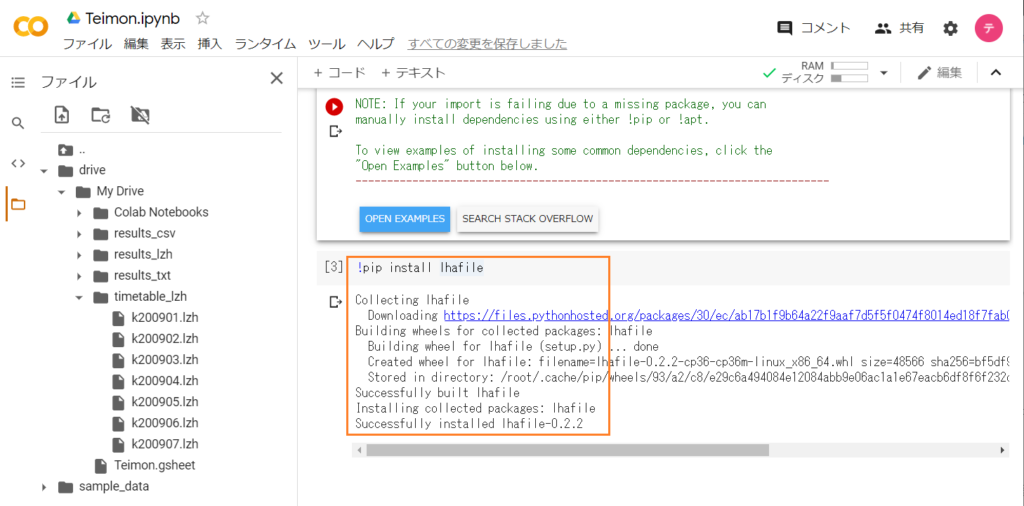
無事にインストールできましたね。それではPythonスクリプトを再度実行します。
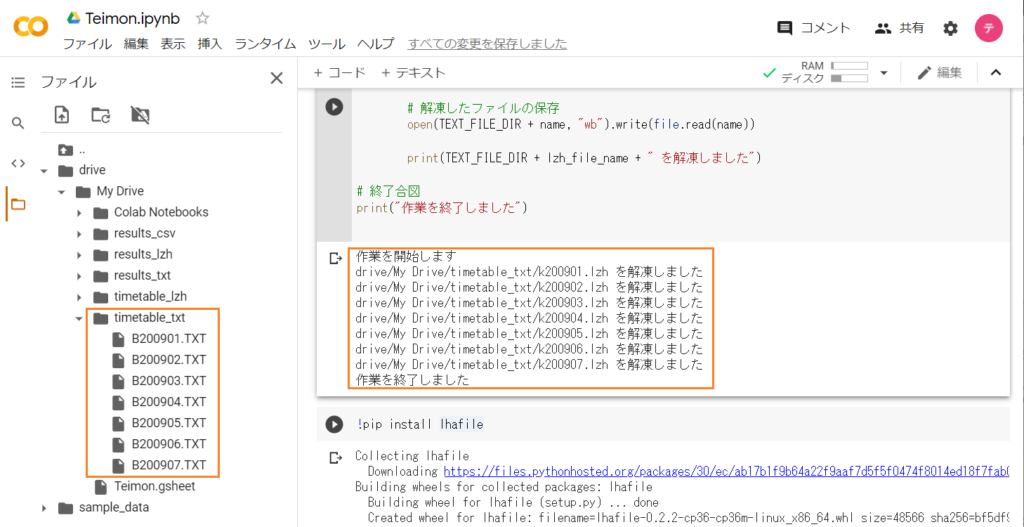
今度は無事に解凍できました。実行結果の表示の下にpipコマンドがありますが、スクリプト(コマンド) の実行はセル単位になるため、セルの位置が上下しても問題ありません。
環境が初期化された場合、モジュールのインストールが再度必要になる点は覚えておきましょう。
さて、次回は番組表の中身を見ていきましょう。
更新履歴
2020/11/23: 文言・スクリプト修正