【python超絶初心者1】pandasでボートレースのいろんな結果をサクッと取得してみた。

明けましておめでとうございます。
2021年新春です。世間では某新型ウイルスの影響で帰省している場合じゃない感じですが、テイモンが帰省してくると言ってしばらく海に還っているいるようなので、pythonについて聞ける人がおらず超絶初心者が一人でググりながら勉強している正月休みです。
今までのデータ取得のおさらい
これまでの「コラボでGO!」シリーズでは、Google Colaboratoryでpythonを実行してボートレースのデータをダウンロードして、CSV化して集計してきました。
Google Colaboratoryの使い方はこちら
ダウンロードはシリーズを過去から遡ってみてね
https://teimon.jp/category/%e3%82%b3%e3%83%a9%e3%83%9c%e3%81%a7go/
もっと手軽に指定した日の結果だけ知りたい
過去どうだったのか、様々な条件で抽出して集計するには全データDLして集計するのが良いのですが、応援舟券の結果検証をするときなどは期間内の全データをダウンロードして集計する必要はなく、特定の場の、特定の日の結果だけがわかればよいということも多々あります。
そこで、ボートレース公式サイトの特定の結果ページからデータを取得する方法を考えてみました。
対象の結果は12/28の江戸川の全レース(下記ページ)としてみました。
https://www.boatrace.jp/owpc/pc/race/resultlist?jcd=03&hd=20201228
結果ページのURLをみると
https://www.boatrace.jp/owpc/pc/race/resultlist?jcd=03&hd=20201228
jcd=03 が江戸川の場コード
hd=20201228 がレースの年月日
というわかりやすいURLになっていることがわかります。
これは応用すれば特定の日の特定の場のURLはすぐに判別できそう。
ちなみに全24場のコード一覧はこちら↓
| 場 | 場コード |
| 桐生 | 01 |
| 戸田 | 02 |
| 江戸川 | 03 |
| 平和島 | 04 |
| 多摩川 | 05 |
| 浜名湖 | 06 |
| 蒲郡 | 07 |
| 常滑 | 08 |
| 津 | 09 |
| 三国 | 10 |
| びわこ | 11 |
| 住之江 | 12 |
| 尼崎 | 13 |
| 鳴門 | 14 |
| 丸亀 | 15 |
| 児島 | 16 |
| 宮島 | 17 |
| 徳山 | 18 |
| 下関 | 19 |
| 若松 | 20 |
| 芦屋 | 21 |
| 福岡 | 22 |
| 唐津 | 23 |
| 大村 | 24 |
北から順にコードがついているようです。
公式サイトの結果をWebスクレイピング
まず最初に考えた方法はHTMLから特定のテキストや画像を抽出するWebスクレイピング。
Webスクレイピングを解説する動画やサイトをたくさん漁ってみたところ、pythonのライブラリのrequestsとBeautifulSoupを利用したWebスクレイピングはたくさん事例がありそうなので、見よう見真似で書いてみました。
#ライブラリインポート
import requests
from bs4 import BeautifulSoup
from time import sleep
#クラスを指定
class Result():
def __init__(self, urls):
self.urls=urls
#HTMLの読み込みを指定
def geturl(self):
result_text=[]
for url in self.urls:
rec=requests.get(url)
cont=rec.content
soup=BeautifulSoup(cont,"html.parser")
#読み取りたいHTML上のclassを指定
result_content=soup.find_all(class_=["numberSet1_row","is-payout1"])
temp=[]
for con in result_content:
out=con.text
temp.append(out)
text=''.join(temp)
result_text.append(text)
#1秒ごとに読み込む
sleep(1)
return result_text
txt=Result(["https://www.boatrace.jp/owpc/pc/race/resultlist?jcd=03&hd=20201228"])
print(txt.geturl())まず最初の3行でライブラリをインポート
requests、BeautifulSoup4、sleepをインポートしています。
その先はこのURLからこの部分のテキストをとってきて、という内容で、赤字の部分で示したとってきたいclass名とURLだけ変更すれば他のページやclassでも再現性があるはずです。
そして取得したのがこちら
['\n4-3-2\n¥8,630\n4-3\n¥1,680\n2-3-6\n¥800\n2-3\n¥360\n1-2-5\n¥6,110\n1-2\n¥650\n6-5-2\n¥18,830\n6-5\n¥3,670\n1-2-3\n¥1,400\n1-2\n¥510\n1-5-3\n¥1,040\n1-5\n¥410\n1-3-4\n¥1,810\n1-3\n¥930\n1-6-4\n¥10,080\n1-6\n¥1,740\n5-4-1\n¥32,660\n5-4\n¥8,240\n1-3-2\n¥910\n1-3\n¥330\n1-3-4\n¥1,630\n1-3\n¥350\n1-3-4\n¥2,110\n1-3\n¥450']3連単の結果と払戻金が取得できましたー。
でもちょっと待て。これじゃ扱いにくいからリストとして成形したりする必要がありそう。
うーーーーん、正規表現使ったり、リスト化したり、カラム付けたり面倒そうだな~~~。っていうか表になってるものをテキストで取得してきてまた表にするって二度手間じゃない?
そう思っていたら、なんと、すごい救世主がいました。
それが、pythonでExcelをいじる人はほぼみんな知っているであろうライブラリ、pandas!
たった6行!pandasで表そのままGETだぜ
勉強のためにいろんなpython関係のサイトや動画をあさっていたら見つけたのがpandasでtableタグで作られている表をそのままとってくるという方法!
スクレイピング必要なかった!
それがこちら!
import pandas as pd
url = 'https://www.boatrace.jp/owpc/pc/race/resultlist?jcd=03&hd=20201228'
dfs = pd.read_html(url)
df = dfs[0]
df.columns = ['レース','3連単組合せ','3連単払戻金','2連単組合せ','2連単払戻金','備考']
dfたった6行!
取得結果はこうなります。
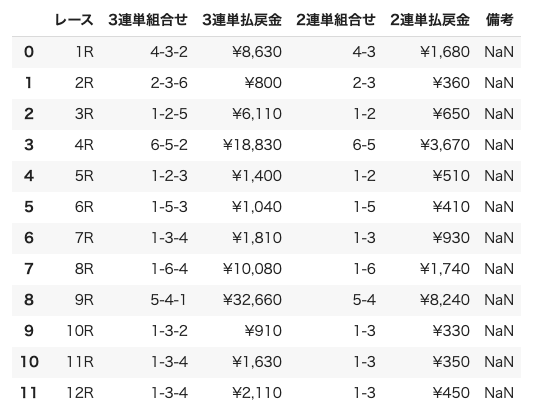
各行の解説コメントも入れてみました。
#ライブラリをインポート
import pandas as pd
#URLを指定
url = 'https://www.boatrace.jp/owpc/pc/race/resultlist?jcd=03&hd=20201228'
dfs = pd.read_html(url)
#0番目のDataFrameを指定
df = dfs[0]
#インデックスを1行に成形
df.columns = ['レース','3連単組合せ','3連単払戻金','2連単組合せ','2連単払戻金','備考']
#DataFrame出力
df実は5行目はなくてもよいのですが、この表、そのままとってくると
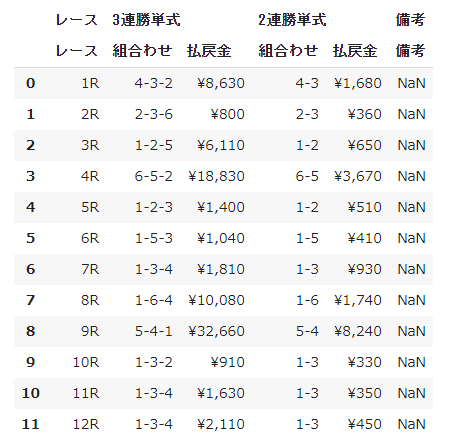
こんな感じでカラム行がMultiIndexという複数行の形になっていて、「このカラムだけとってきて」というような指定をするのがちょっと面倒なので1行のカラムになるよう変更するために5行目を入れています。
複数のページやデータを取得する場合はsleepを入れてk取得しにいく間隔をあけた方が良いかと思いますが、URLが固定でひとつのデータを取ってくるだけなら最短これでいけそうです。
これは応用がききそうだ
今回はまだ「ブラウザでそのページ開いてコピペすりゃいいじゃん」というレベルなので、今後これをCSV化したり、複数の日程まとめて取得したりする方法をやっていこうと思います。
しかもボートレース公式のサイトはこの結果一覧ページ以外にもシンプルな法則でURLが決められており、またbodyの中もわかりやすいtableで組まれているページが他にもあるので、さらに色々なデータをサクッと見たいときに応用がききそうです。
応用編はまた追々。
[affi id=7]