

あいかわらずpython超絶初心者です。あのアザラシの妖精は最近本業が忙しいとか言って何も教えてくれません。
先日はボートレース公式サイトのある日のある場の結果一覧ページから一節間の全レースの2連単と3連単の結果と払戻金をPythonのライブラリpandasを使って簡単に取ってきて、csv化してみました。
でも、場コード覚えるのちょっと面倒。
そこで、「江戸川」「戸田」「住之江」のようにボートレース場名を入れたら勝手に場コードが入るようにしたいと思いました。
場コードリストを作った
まずはpythonで読み込む場コードリストを作りましょう。
はい、できた。
| place | code |
| 桐生 | 01 |
| 戸田 | 02 |
| 江戸川 | 03 |
| 平和島 | 04 |
| 多摩川 | 05 |
| 浜名湖 | 06 |
| 蒲郡 | 07 |
| 常滑 | 08 |
| 津 | 09 |
| 三国 | 10 |
| びわこ | 11 |
| 住之江 | 12 |
| 尼崎 | 13 |
| 鳴門 | 14 |
| 丸亀 | 15 |
| 児島 | 16 |
| 宮島 | 17 |
| 徳山 | 18 |
| 下関 | 19 |
| 若松 | 20 |
| 芦屋 | 21 |
| 福岡 | 22 |
| 唐津 | 23 |
| 大村 | 24 |
こちらをCSVで書き出して、ローカル環境に置いておきましょう。(私はGoogleDrive場に置いたけど)
そしてこちらをpandasで読み込めるか確認します。
# 場コードのCSVを取ってきます。一桁の数字の0が消えないようにstring型にし、場名をインデックスにします
placecode = pd.read_csv('drive/My Drive/teimon_practice/placecode.csv', dtype=str, index_col=0)
# "●●●"内の場名は手打ち
PLACE = '江戸川'
# 場コードCSVからPLACEと同じcodeをとりだそう
print(placecode.loc[PLACE,'code'])
こちらを実行すると
03
江戸川の場コード 03が表示されます。
場名を書いたら場コードが代入されるようにした
これで場名さえわかれば場コードを覚えなくてよいようになったぞ。
さて、前回書いた結果一覧をCSVにするコードにぶっこもう。
はいできた。
#ライブラリをインポート
import pandas as pd
# OSの機能を利用するパッケージ os をインポート
import os
from os import makedirs
# 時間を制御する time モジュールをインポート
from time import sleep
# HTTP通信ライブラリの requests モジュールをインポート
from requests import get
# 日付を扱うための datetime モジュールをインポート
from datetime import datetime as dt
from datetime import timedelta as td
# 格納するディレクトリを決める
CSV_FILE_DIR = "drive/My Drive/teimon_practice/table/"
# CSVファイルを保存するフォルダを作成
os.makedirs(CSV_FILE_DIR, exist_ok=True)
# 開始日と終了日を指定(YYYY-MM-DD)
START_DATE = "2020-12-24"
END_DATE = "2020-12-28"
# 開始日と終了日を日付型に変換して格納
start_date = dt.strptime(START_DATE, '%Y-%m-%d')
end_date = dt.strptime(END_DATE, '%Y-%m-%d')
# 日付の差から期間を計算
days_num = (end_date - start_date).days + 1
# 日付リストを格納する変数
date_list = []
# 日付リストを生成
for i in range(days_num):
# 開始日から日付を順に取得
target_date = start_date + td(days=i)
# 日付型を文字列に変換してリストに格納(YYYYMMDD)
date_list.append(target_date.strftime("%Y%m%d"))
# URLの固定部分を指定
FIXED_URL = "https://www.boatrace.jp/owpc/pc/race/resultlist?jcd="
# 場コードを取得して指定。場名は自分で入れる
placecode = pd.read_csv('drive/My Drive/teimon_practice/placecode.csv', dtype=str, index_col=0)
PLACE = '江戸川'
# 作業始まったら合図をもらおう
print("作業を開始します。")
# URL生成とダウンロード
for date in date_list:
dfs = pd.read_html(FIXED_URL + placecode.loc[PLACE,'code'] + "&hd=" + date )
#0番目のDataFrameを指定
df = dfs[0]
# インデックスを1行に成形
df.columns = ['レース','3連単組合せ','3連単払戻金','2連単組合せ','2連単払戻金','備考']
# 場コードを代入してファイル名作ろう
df.to_csv( CSV_FILE_DIR + placecode.loc[PLACE,'code'] + "_" + date + ".csv" , encoding="shift_jis")
# リクエスト間隔を指定(秒) ※サーバに負荷をかけないよう3秒以上を推奨
INTERVAL = 3
# 作業終わったら合図をもらおう
print("作業を終了しました。")これで赤字の部分、日付と場名を変えるだけで結果一覧がCSV化できました。
着順データもCSV化した
今度は同じページにある着順一覧、こちらの表も取得したいと思います。
これです↓

でもこの表、上の「勝式・払戻金・結果」の表よりも不要なものがたくさんあります。
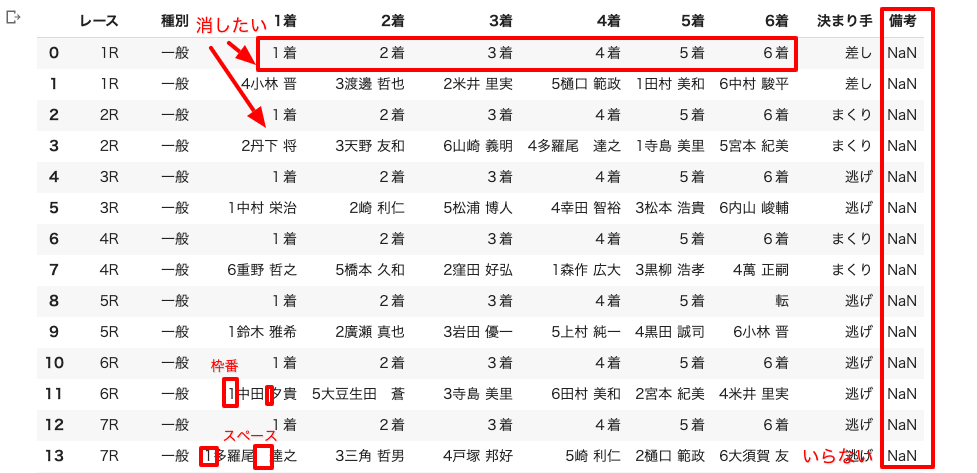
不要な行や空白を消したり、枠番と選手名を分けたりした
1.行ごとに入っている「1着」「2着」等の着順行を削除
2.備考欄もあまり使わないから削除
3.選手名の姓と名の間に入っているスペースを削除
(基本的に半角スペースだけど、名字が3字の場合だけなぜか全角スペース)
4.枠番と名前を別の列にする
なんだかもっとシンプルにできそうな気がしますがとりあえずできたぞっていうのはこちら
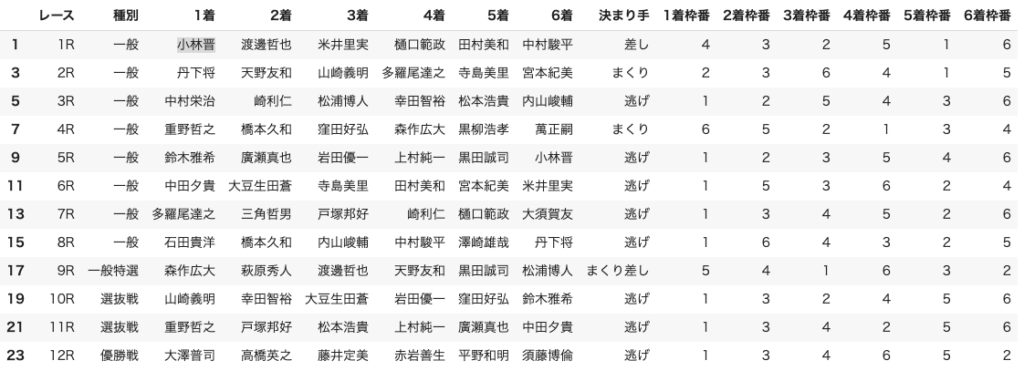
書いたコードはこんな感じ。多分もっとキレイキレイできるはず。む〜〜〜ん
# pandasインポート
import pandas as pd
# URLを指定
url = 'https://www.boatrace.jp/owpc/pc/race/resultlist?jcd=03&hd=20201228'
dfs = pd.read_html(url)
#1番目のDataFrameを指定
df = dfs[1]
# インデックスを指定
df.columns = ['レース','種別','1着','2着','3着','4着','5着','6着','決まり手','備考']
# 備考欄を削除
del df['備考']
# 偶数行を削除(df2に名前変えました)
df2 = df.drop([0,2,4,6,8,10,12,14,16,18,20,22])
# 選手名が入っている列の半角スペースと全角スペースを削除
df2['1着'] = df2['1着'].str.replace(' ', '').str.replace(' ', '')
df2['2着'] = df2['2着'].str.replace(' ', '').str.replace(' ', '')
df2['3着'] = df2['3着'].str.replace(' ', '').str.replace(' ', '')
df2['4着'] = df2['4着'].str.replace(' ', '').str.replace(' ', '')
df2['5着'] = df2['5着'].str.replace(' ', '').str.replace(' ', '')
df2['6着'] = df2['6着'].str.replace(' ', '').str.replace(' ', '')
# 選手名の列に入っている枠番(半角数字)を抽出して別の列にして、元の列からは1文字目以降を抽出
df2['1着枠番'] = df2['1着'].str.extract('(\d)')
df2['1着'] = df2['1着'].str[1:]
df2['2着枠番'] = df2['2着'].str.extract('(\d)')
df2['2着'] = df2['2着'].str[1:]
df2['3着枠番'] = df2['3着'].str.extract('(\d)')
df2['3着'] = df2['3着'].str[1:]
df2['4着枠番'] = df2['4着'].str.extract('(\d)')
df2['4着'] = df2['4着'].str[1:]
df2['5着枠番'] = df2['5着'].str.extract('(\d)')
df2['5着'] = df2['5着'].str[1:]
df2['6着枠番'] = df2['6着'].str.extract('(\d)')
df2['6着'] = df2['6着'].str[1:]
# 表示する
df2コラボでGO!でおさらい
ここからさらに選手名に選手の登録番号も入れたらさらに集計が楽になりそう。
でもそのためにはたくさんfor文書かなきゃいけなそうなのでちょっとテイモンが書いた以前の「コラボでGO!」シリーズで勉強してきます。


