無人島
競走成績と番組表ってどっちも大事なんだよ。
どっちか1つだけ無人島に持って行けるとしたらどうする?
むっ、ムー、Muuu、、、ピーカー!!
テイモンが壊れた。
競走成績の抽出
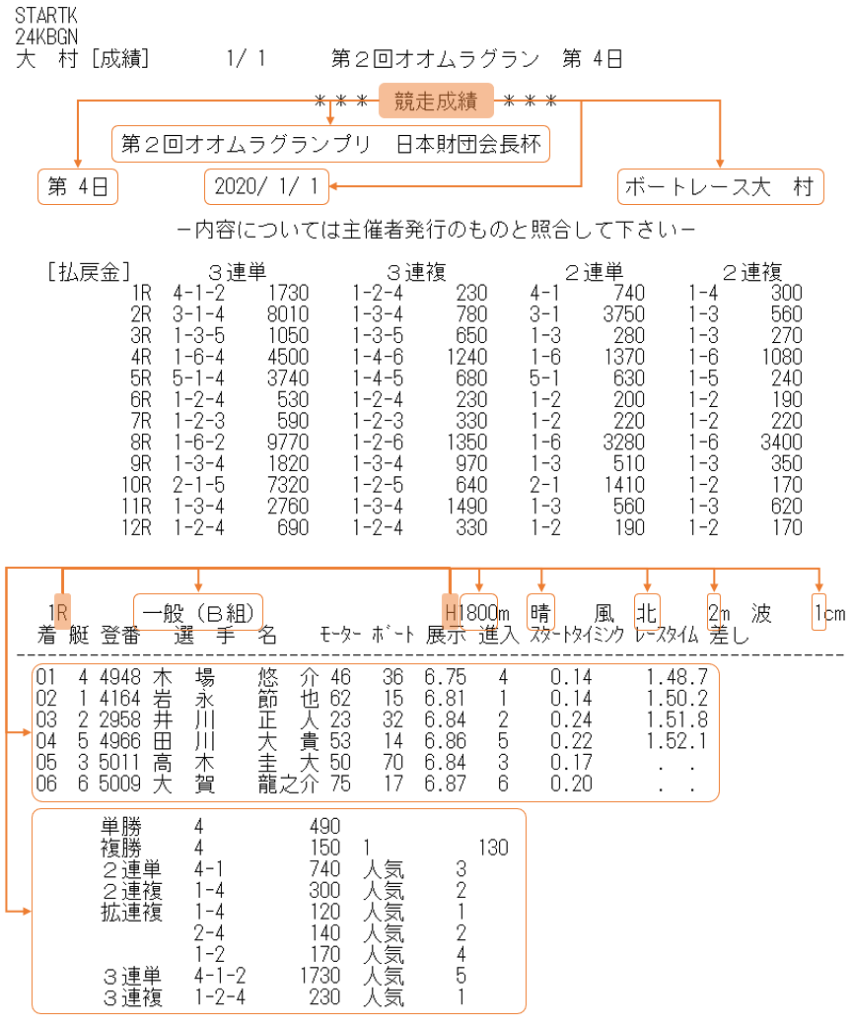
競争成績のファイルからデータを抽出する方法は、コラボでGO!(5)でも紹介しましたね。下図のようにキーワード「競争成績」から相対的な位置を指定することで、目的のデータを抽出しました。
他のデータを抽出する際も考え方は同じです。
今回は競争成績の詳細データを取得しますが、キーワードは「R」と「H」です。これは詳細データの1行目にある「レース回のR」と「距離のH」に他なりません。
「風」や「波」を使うことも可能ですが、もし波風さんというレーサーが登録された場合に困ったことになるので、そういった可能性が低いものをキーワードとして設定します。
前処理
前処理とはデータを分析しやすくするためにデータに手を加えることを言います。ここでは、競走成績のテキストファイルからデータを抽出する際に行う前処理について解説します。
1つ目は「進入固定」の処理です。
レース名に「進入固定」という文字列が割り込むと、レース名の後ろにあるデータの位置がズレてしまうことが分かっています。そこで、この文字列が割り込んだ際に文字列の長さを調整する処理を入れます。
# レース名にキーワード「進入固定」が割り込んだ際の補正(「進入固定戦隊」は除くためHまで含めて置換)
if re.search(r"進入固定", line):
line = line.replace('進入固定 H', '進入固定 H')2つ目は「特払い」の処理です。
これは進入固定と同様の事象で、特払いが発生した際にやはり後ろに続くデータの位置がズレてしまう現象です。これも文字列の長さを調整します。
# 文字列「特払い」が割り込んだ際の補正
if re.search(r"特払い", line):
line = line.replace(' 特払い ', ' 特払い ')3つ目は「レースコード」の作成です。
レースコードは競走成績のテキストファイルに含まれていないため、自前で生成します。レースコードの形式は「日付+レース場の3レターコード+レース回」です。
3レターコードは場コードにも代替可能ですが、文字で示す方が視認性が高いため、テイモンでは勝手に決めた3レターコードをレースコードに組み込んでいます。
# レースコードを生成
dict_stadium = {'桐生': 'KRY', '戸田': 'TDA', '江戸川': 'EDG', '平和島': 'HWJ',
'多摩川': 'TMG', '浜名湖': 'HMN', '蒲郡': 'GMG', '常滑': 'TKN',
'津': 'TSU', '三国': 'MKN', '琵琶湖': 'BWK', '住之江': 'SME',
'尼崎': 'AMG', '鳴門': 'NRT', '丸亀': 'MRG', '児島': 'KJM',
'宮島': 'MYJ', '徳山': 'TKY', '下関': 'SMS', '若松': 'WKM',
'芦屋': 'ASY', '福岡': 'FKO', '唐津': 'KRT', '大村': 'OMR'
}
race_code = date[0:4] + date[5:7] + date[8:10] + dict_stadium[stadium] + race_round[0:2]この他にも、文字列の置換やスペースの削除を行なっていますが、ここでは説明を割愛します。
Pythonスクリプトの記述
これが競走成績に含まれる全てのデータを抽出してCSVファイルを吐き出すスクリプトです。コラボにコピペして実行してみましょう。
なお、このファイルを実行するには競走成績のファイルがダウンロードされており、かつファイルが解凍されていることが前提となります。
ファイルのダウンロードについては『コラボでGO!(3)』、解凍については『コラボでGO!(4)』を参照してください。
# 解凍したテキストファイルの格納先を指定
TEXT_FILE_DIR = "drive/My Drive/results_txt/"
# CSVファイルの保存先を指定
CSV_FILE_DIR = "drive/My Drive/results_csv_detail/"
# CSVファイルの名前を指定 ※YYYYMMDDには対象期間を入力
CSV_FILE_NAME = "results_YYYYMMDD-YYYYMMDD.csv"
# CSVファイルのヘッダーを指定
CSV_FILE_HEADER = "レースコード,タイトル,日次,レース日,レース場,\
レース回,レース名,距離(m),天候,風向,風速(m),波の高さ(cm),決まり手,\
単勝_艇番,単勝_払戻金,複勝_1着_艇番,複勝_1着_払戻金,複勝_2着_艇番,複勝_2着_払戻金,\
2連単_組番,2連単_払戻金,2連単_人気,2連複_組番,2連複_払戻金,2連複_人気,\
拡連複_1-2着_組番,拡連複_1-2着_払戻金,拡連複_1-2着_人気,\
拡連複_1-3着_組番,拡連複_1-3着_払戻金,拡連複_1-3着_人気,\
拡連複_2-3着_組番,拡連複_2-3着_払戻金,拡連複_2-3着_人気,\
3連単_組番,3連単_払戻金,3連単_人気,3連複_組番,3連複_払戻金,3連複_人気,\
1着_着順,1着_艇番,1着_登録番号,1着_選手名,1着_モーター番号,1着_ボート番号,\
1着_展示タイム,1着_進入コース,1着_スタートタイミング,1着_レースタイム,\
2着_着順,2着_艇番,2着_登録番号,2着_選手名,2着_モーター番号,2着_ボート番号,\
2着_展示タイム,2着_進入コース,2着_スタートタイミング,2着_レースタイム,\
3着_着順,3着_艇番,3着_登録番号,3着_選手名,3着_モーター番号,3着_ボート番号,\
3着_展示タイム,3着_進入コース,3着_スタートタイミング,3着_レースタイム,\
4着_着順,4着_艇番,4着_登録番号,4着_選手名,4着_モーター番号,4着_ボート番号,\
4着_展示タイム,4着_進入コース,4着_スタートタイミング,4着_レースタイム,\
5着_着順,5着_艇番,5着_登録番号,5着_選手名,5着_モーター番号,5着_ボート番号,\
5着_展示タイム,5着_進入コース,5着_スタートタイミング,5着_レースタイム,\
6着_着順,6着_艇番,6着_登録番号,6着_選手名,6着_モーター番号,6着_ボート番号,\
6着_展示タイム,6着_進入コース,6着_スタートタイミング,6着_レースタイム,\n"
# OSの機能を利用するパッケージ os をインポート
import os
# 正規表現をサポートするモジュール re をインポート
import re
# テキストファイルからデータを抽出し、CSVファイルに書き込む関数 get_data を定義
def get_data(text_file):
# CSVファイルを追記モードで開く
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "a", encoding="shift_jis")
# テキストファイルから中身を順に取り出す
for line in text_file:
# キーワード「競争成績」を見つけたら(rは正規表現でraw文字列を指定するおまじない)
if re.search(r"競走成績", line):
# 1行スキップ
text_file.readline()
# タイトルを格納
line = text_file.readline()
title = line[:-1].strip()
# 1行スキップ
text_file.readline()
# 日次・レース日・レース場を格納
line = text_file.readline()
day = line[3:7].replace(' ', '')
date = line[17:27].replace(' ', '0')
stadium = line[62:65].replace(' ', '')
# レース回の「R」と距離の「H」を同じ行に見つけたら -> これ以降に競走成績の詳細が記載
if re.search(r"R", line) and re.search(r"H", line):
# レース名にキーワード「進入固定」が割り込んだ際の補正(「進入固定戦隊」は除くためHまで含めて置換)
if re.search(r"進入固定", line):
line = line.replace('進入固定 H', '進入固定 H')
# レース回、レース名、距離(m)、天候、風向、風速(m)、波の高さ(cm)を取得
race_round = line[2:5].replace(' ', '0')
race_name = line[12:31].replace(' ', '')
distance = line[36:40]
weather = line[43:45].strip()
wind_direction = line[50:52].strip()
wind_velocity = line[53:55].strip()
wave_height = line[60:63].strip()
# 決まり手を取得
line = text_file.readline()
winning_technique = line[50:55].strip()
# 1行スキップ
text_file.readline()
# 選手データを格納する変数を定義
result_racer = ""
# 選手データを取り出す行(開始行)を格納
line = text_file.readline()
# 空行まで処理を繰り返す = 1~6艇分の選手データを取得
while line != "\n":
# 選手データを格納(行末にカンマが入らないように先頭にカンマを入れる)
result_racer += "," + line[2:4] + "," + line[6] + "," + line[8:12] \
+ "," + line[13:21] + "," + line[22:24] + "," + line[27:29] \
+ "," + line[30:35].strip() + "," + line[38] + "," + line[43:47] \
+ "," + line[52:58]
# 次の行を読み込む
line = text_file.readline()
# レース結果を取り出す行(開始行)を格納
line = text_file.readline()
# 空行まで処理を繰り返す = レース結果を取得
while line != "\n":
# 単勝の結果を取得
if re.search(r"単勝", line):
# 文字列「特払い」が割り込んだ際の補正
if re.search(r"特払い", line):
line = line.replace(' 特払い ', ' 特払い ')
result_win = line[15] + "," + line[22:29].strip()
# 複勝の結果を取得
if re.search(r"複勝", line):
# 文字列「特払い」が割り込んだ際の補正
if re.search(r"特払い", line):
line = line.replace(' 特払い ', ' 特払い ')
# 複勝_2着のデータが存在しない場合の分岐
if len(line) <= 33:
result_place_show = line[15] + "," + line[22:29].strip() \
+ "," + ","
else:
result_place_show = line[15] + "," + line[22:29].strip() \
+ "," + line[31] + "," + line[38:45].strip()
# 2連単の結果を取得
if re.search(r"2連単", line):
result_exacta = line[14:17] + "," + line[21:28].strip() \
+ "," + line[36:38].strip()
# 2連複の結果を取得
if re.search(r"2連複", line):
result_quinella = line[14:17] + "," + line[21:28].strip() \
+ "," + line[36:38].strip()
# 拡連複の結果を取得
if re.search(r"拡連複", line):
# 1-2着
result_quinella_place = line[14:17] + "," + line[21:28].strip() \
+ "," + line[36:38].strip()
# 1-3着
line = text_file.readline()
result_quinella_place += "," + line[17:20] + "," + line[24:31].strip() \
+ "," + line[39:41].strip()
# 2-3着
line = text_file.readline()
result_quinella_place += "," + line[17:20] + "," + line[24:31].strip() \
+ "," + line[39:41].strip()
# 3連単の結果を取得
if re.search(r"3連単", line):
result_trifecta = line[14:19] + "," + line[21:28].strip() \
+ "," + line[35:38].strip()
# 3連複の結果を取得
if re.search(r"3連複", line):
result_trio = line[14:19] + "," + line[21:28].strip() \
+ "," + line[35:38].strip()
# 次の行を読み込む
line = text_file.readline()
# レースコードを生成
dict_stadium = {'桐生': 'KRY', '戸田': 'TDA', '江戸川': 'EDG', '平和島': 'HWJ',
'多摩川': 'TMG', '浜名湖': 'HMN', '蒲郡': 'GMG', '常滑': 'TKN',
'津': 'TSU', '三国': 'MKN', '琵琶湖': 'BWK', '住之江': 'SME',
'尼崎': 'AMG', '鳴門': 'NRT', '丸亀': 'MRG', '児島': 'KJM',
'宮島': 'MYJ', '徳山': 'TKY', '下関': 'SMS', '若松': 'WKM',
'芦屋': 'ASY', '福岡': 'FKO', '唐津': 'KRT', '大村': 'OMR'
}
race_code = date[0:4] + date[5:7] + date[8:10] + dict_stadium[stadium] + race_round[0:2]
# 抽出したデータをCSVファイルに書き込む
csv_file.write(race_code + "," + title + "," + day + "," + date + "," + stadium \
+ "," + race_round + "," + race_name + "," + distance + "," + weather \
+ "," + wind_direction + "," + wind_velocity + "," + wave_height \
+ "," + winning_technique + "," + result_win + "," + result_place_show \
+ "," + result_exacta + "," + result_quinella + "," + result_quinella_place \
+ "," + result_trifecta + "," + result_trio + result_racer + "\n")
# CSVファイルを閉じる
csv_file.close()
# 開始合図
print("作業を開始します")
# CSVファイルを格納するフォルダを作成
os.makedirs(CSV_FILE_DIR, exist_ok=True)
# CSVファイルを作成しヘッダ情報を書き込む
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "w", encoding="shift_jis")
csv_file.write(CSV_FILE_HEADER)
csv_file.close()
# テキストファイルのリストを取得
text_file_list = os.listdir(TEXT_FILE_DIR)
# リストからファイル名を順に取り出す
for text_file_name in text_file_list:
# 拡張子が TXT のファイルに対してのみ実行
if re.search(".TXT", text_file_name):
# テキストファイルを開く
text_file = open(TEXT_FILE_DIR + text_file_name, "r", encoding="shift_jis")
# 関数 get_data にファイル(オブジェクト)を渡す
get_data(text_file)
# テキストファイルを閉じる
text_file.close()
print(CSV_FILE_DIR + CSV_FILE_NAME + " を作成しました")
# 終了合図
print("作業を終了しました")
番組表と結合する
もっとコラボでGO!(5)では、番組表のファイルからデータを抽出し、レースコードを付与してCSVファイルを作成するPythonスクリプトを紹介しました。この出力結果を利用すれば、レースコードを介して競争成績と番組表を結合できますね。
番組表で取りこぼしたデータはありませんので、これでダウンロードできる2つのファイルから取得できるデータは、すべて揃ったことになります。
まずはデータをよく眺め、どのような分析ができるのか考えてみましょう。