

偏差値教育
キョーコは学生のとき何の科目が得意だった?
体育が少し苦手なくらいで、それ以外はほとんど5だったよ。もちろん5段階評価。
(偏差値教育に偏るとこうなるんだな…)
何が言いたい。
データとして面白いかも
ボートレースの公式サイトでは、競走成績や番組表の他に「レーサー期別成績」をダウンロードすることができます。
このデータは競走成績や番組表と異なり、シンプルな固定長データとなっているため(テイモンとしては)面白みがなく、これまで紹介する機会がありませんでした。
ただ、キョーコがレーサー期別成績を使って面白そうな分析をしているので、このシリーズでも取り上げることにしました。キョーコ成長したな。。。
ここではレーサー期別成績のダウンロード・解凍・CSV化をPythonで自動化する方法を紹介します。
レーサー期別成績の「期」とは
レーサー期別成績とはその名の通り、ボートレーサーの期別の成績です。前期・後期に別れており、それぞれの集計期間は次の通りです。
- 前期: 05月01日 から 同年10月31日 までの6ヶ月
- 後期: 11月01日 から 翌年04月30日 までの6ヶ月
前期・後期は「審査期間」であることに注意してください。審査期間とは、レーサーの級別を決める審査対象となる期間です。レーサー期別成績のファイルは、この審査期間の単位で用意されています。
例えば、公式サイトで「前期」と表記されたファイルはその前の年の前期のデータが収められているのですが、間違えやすいところなので表にまとめました。
| 公式サイトの表記 | 集計期間(審査期間) | 適用期間(審査結果の級が適用される期間) |
| 2021年 前期 | 2020年05月01日〜2020年10月31日 | 2021年01月01日〜2021年06月30日 |
| 2020年 後期 | 2019年11月01日〜2020年04月30日 | 2020年07月01日〜2020年12月31日 |
| 2020年 前期 | 2019年05月01日〜2019年10月31日 | 2020年01月01日〜2020年06月30日 |
| 公式サイトの表記 | ファイル名 | ファイル作成日 |
| 2021年 前期 | fan2010.lzh | 2020年11月16日 |
| 2020年 後期 | fan2004.lzh | 2020年06月04日 |
| 2020年 前期 | fan1910.lzh | 2019年12月09日 |
ダウンロードの自動化を考えるに当たっては、集計期間とファイル名に注目しましょう。ファイル名は集計期間の最終年月が変数となっていますね。
公式サイトの表記を気にすると間違えますので、いつの期間のデータを収集するのかを意識してスクリプトを書くようにしましょう。
レーサー期別成績のダウンロード
繰り返しになりますが、集計期間には次の2種類があります。
- 前期: 05月01日 から 同年10月31日 までの6ヶ月
- 後期: 11月01日 から 翌年04月30日 までの6ヶ月
そしてファイル名は集計期間の最終年月で区別されていますので、この最終年月を定数として直接スクリプトに書き込むのが手っ取り早いと考えられます。
# 集計期間の最終年月を指定(YYMM)
# 前期は05/01-10/31、後期は11/01-04/30。したがってMMは10または04のみ
PERIOD_LIST = [
"1810",
"1904",
"1910",
"2004",
"2010"
]上記の例の場合、ダウンロードするファイルは次の5つとなります。
| 集計期間の最終年月 | 集計期間 | ファイル名 |
| 1810 | 2018年05月01日〜2018年10月31日 | fan1810.lzh |
| 1904 | 2018年11月01日〜2019年04月30日 | fan1904.lzh |
| 1910 | 2019年05月01日〜2019年10月31日 | fan1910.lzh |
| 2004 | 2019年11月01日〜2020年04月30日 | fan2004.lzh |
| 2010 | 2020年05月01日〜2020年10月31日 | fan2010.lzh |
この定数から取得したいファイルのURLを生成し、順番にダウンロードすることにしましょう。全体のスクリプトは次の通りです。コラボにコピペして実行できます。
# 集計期間の最終年月を指定(YYMM)
# 前期は05/01-10/31、後期は11/01-04/30。したがってMMは10または04のみ
PERIOD_LIST = [
"1810",
"1904",
"1910",
"2004",
"2010"
]
# ファイルの保存先を指定 ※コラボでGoogleドライブをマウントした状態を想定
SAVE_DIR = "drive/My Drive/racer_lzh/"
# リクエスト間隔を指定(秒) ※サーバに負荷をかけないよう3秒以上を推奨
INTERVAL = 3
# URLの固定部分を指定
FIXED_URL = "https://www.boatrace.jp/static_extra/pc_static/download/data/kibetsu/"
# HTTP通信ライブラリの requests モジュールから get をインポート
from requests import get
# OSの機能を利用する os モジュールから makedirs をインポート
from os import makedirs
# 時間を制御する time モジュールから sleep をインポート
from time import sleep
# 開始合図
print("作業を開始します")
# ファイルを保存するフォルダを作成
makedirs(SAVE_DIR, exist_ok=True)
# 集計期間のリストから集計期間を順に取り出す
for period in PERIOD_LIST:
# URLとファイル名を生成
variable_url = FIXED_URL + "fan" + period + ".lzh"
file_name = "fan" + period + ".lzh"
# 生成したURLでファイルをダウンロード
r = get(variable_url)
# 成功した場合
if r.status_code == 200:
# ファイル名を指定して保存
f = open(SAVE_DIR + file_name, 'wb')
f.write(r.content)
f.close()
print(variable_url + " をダウンロードしました")
# 失敗した場合
else:
print(variable_url + " のダウンロードに失敗しました")
# 指定した間隔をあける
sleep(INTERVAL)
# 終了合図
print("作業を終了しました")レーサー期別成績の解凍
レーサー期別成績のファイルは、競走成績や番組表と同じlzh形式で圧縮されているため、過去のスクリプトを流用して解凍しましょう。
コラボで実行する際は、先にpipコマンドを打ってlhaモジュールをインストールすることを忘れずに。
# ダウンロードしたLZHファイルの格納先を指定
LZH_FILE_DIR = "drive/My Drive/racer_lzh/"
# ファイルの解凍先を指定
TEXT_FILE_DIR = "drive/My Drive/racer_txt/"
# LZH形式のファイルを解凍するパッケージ lhafile をインポート
import lhafile
# OSの機能を利用するパッケージ os をインポート
import os
# 正規表現をサポートするモジュール re をインポート
import re
# 開始合図
print("作業を開始します")
# ファイルを保存するフォルダを作成
os.makedirs(TEXT_FILE_DIR, exist_ok=True)
# LZHファイルのリストを取得
lzh_file_list = os.listdir(LZH_FILE_DIR)
# リストからファイル名を順に取り出す
for lzh_file_name in lzh_file_list:
# 拡張子が lzh のファイルに対してのみ実行
if re.search(".lzh", lzh_file_name):
# LZHファイルを解凍
file = lhafile.Lhafile(LZH_FILE_DIR + lzh_file_name)
# 解凍したファイルの名前を取得
info = file.infolist()
file_name = info[0].filename
# ファイル名を指定して保存
f = open(TEXT_FILE_DIR + file_name, 'wb')
f.write(file.read(file_name))
f.close()
print(TEXT_FILE_DIR + lzh_file_name + " を解凍しました")
# 終了合図
print("作業を終了しました")レーサー期別成績のCSV化
ファイルが解凍できたらいよいよCSV化です。データを取得するカラムが多いため、その分スクリプトが長くなっています。
特に難しいところはありませんが、CSV化するタイミングでクレンジングを行った方が良いでしょう。ここでは名前漢字のスペース除去や名前カナのトリム、小数点の挿入などを行っています。
# 解凍したテキストファイルの格納先を指定
TEXT_FILE_DIR = "drive/My Drive/racer_txt/"
# CSVファイルの保存先を指定
CSV_FILE_DIR = "drive/My Drive/racer_csv/"
# CSVファイルの名前を指定 ※YYYYMMDDには対象期間を入力
CSV_FILE_NAME = "racer_YYMM-YYMM.csv"
# CSVファイルのヘッダーを指定
CSV_FILE_HEADER = "登番,名前漢字,名前カナ,支部,級,年号,生年月日,性別,年齢,身長,体重,血液型,\
勝率,複勝率,1着回数,2着回数,出走回数,優出回数,優勝回数,平均スタートタイミング,\
1コース進入回数,1コース複勝率,1コース平均スタートタイミング,1コース平均スタート順位,\
2コース進入回数,2コース複勝率,2コース平均スタートタイミング,2コース平均スタート順位,\
3コース進入回数,3コース複勝率,3コース平均スタートタイミング,3コース平均スタート順位,\
4コース進入回数,4コース複勝率,4コース平均スタートタイミング,4コース平均スタート順位,\
5コース進入回数,5コース複勝率,5コース平均スタートタイミング,5コース平均スタート順位,\
6コース進入回数,6コース複勝率,6コース平均スタートタイミング,6コース平均スタート順位,\
前期級,前々期級,前々々期級,前期能力指数,今期能力指数,年,期,算出期間(自),算出期間(至),養成期,\
1コース1着回数,1コース2着回数,1コース3着回数,1コース4着回数,1コース5着回数,1コース6着回数,1コースF回数,\
1コースL0回数,1コースL1回数,1コースK0回数,1コースK1回数,1コースS0回数,1コースS1回数,1コースS2回数,\
2コース1着回数,2コース2着回数,2コース3着回数,2コース4着回数,2コース5着回数,2コース6着回数,2コースF回数,\
2コースL0回数,2コースL1回数,2コースK0回数,2コースK1回数,2コースS0回数,2コースS1回数,2コースS2回数,\
3コース1着回数,3コース2着回数,3コース3着回数,3コース4着回数,3コース5着回数,3コース6着回数,3コースF回数,\
3コースL0回数,3コースL1回数,3コースK0回数,3コースK1回数,3コースS0回数,3コースS1回数,3コースS2回数,\
4コース1着回数,4コース2着回数,4コース3着回数,4コース4着回数,4コース5着回数,4コース6着回数,4コースF回数,\
4コースL0回数,4コースL1回数,4コースK0回数,4コースK1回数,4コースS0回数,4コースS1回数,4コースS2回数,\
5コース1着回数,5コース2着回数,5コース3着回数,5コース4着回数,5コース5着回数,5コース6着回数,5コースF回数,\
5コースL0回数,5コースL1回数,5コースK0回数,5コースK1回数,5コースS0回数,5コースS1回数,5コースS2回数,\
6コース1着回数,6コース2着回数,6コース3着回数,6コース4着回数,6コース5着回数,6コース6着回数,6コースF回数,\
6コースL0回数,6コースL1回数,6コースK0回数,6コースK1回数,6コースS0回数,6コースS1回数,6コースS2回数,\
コースなしL0回数,コースなしL1回数,コースなしK0回数,コースなしK1回数,出身地\n"
# OSの機能を利用するパッケージ os をインポート
import os
# 正規表現をサポートするモジュール re をインポート
import re
# テキストファイルからデータを抽出し、CSVファイルに書き込む関数 get_data を定義
def get_data(text_file):
# CSVファイルを追記モードで開く
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "a", encoding="shift_jis")
# テキストファイルから中身を順に取り出す
for line in text_file:
# 空行まで処理を繰り返す
while line != "\n":
# レーサー期別成績を格納 ※"."は小数点を付与したもの
racer_data = line[0:4] + "," + \
line[4:8].replace(' ', '') + " " + line[8:12].replace(' ', '') + "," + \
line[12:27].strip() + "," + \
line[27:29] + "," + line[29:31] + "," + line[31:32] + "," + \
line[32:38] + "," + line[38:39] + "," + line[39:41] + "," + \
line[41:44] + "," + line[44:46] + "," + line[46:48].strip() + "," + \
line[48:50] + "." + line[50:52] + "," + \
line[52:55] + "." + line[55:56] + "," + \
line[56:59] + "," + line[59:62] + "," + line[62:65] + "," + \
line[65:67] + "," + line[67:69] + "," + \
line[69:70] + "." + line[70:72] + "," + \
line[72:75] + "," + \
line[75:78] + "." + line[78:79] + "," + \
line[79:80] + "." + line[80:82] + "," + \
line[82:83] + "." + line[83:85] + "," + \
line[85:88] + "," + \
line[88:91] + "." + line[91:92] + "," + \
line[92:93] + "." + line[93:95] + "," + \
line[95:96] + "." + line[96:98] + "," + \
line[98:101] + "," + \
line[101:104] + "." + line[104:105] + "," + \
line[105:106] + "." + line[106:108] + "," + \
line[108:109] + "." + line[109:111] + "," + \
line[111:114] + "," + \
line[114:117] + "." + line[117:118] + "," + \
line[118:119] + "." + line[119:121] + "," + \
line[121:122] + "." + line[122:124] + "," + \
line[124:127] + "," + \
line[127:130] + "." + line[130:131] + "," + \
line[131:132] + "." + line[132:134] + "," + \
line[134:135] + "." + line[135:137] + "," + \
line[137:140] + "," + \
line[140:143] + "." + line[143:144] + "," + \
line[144:145] + "." + line[145:147] + "," + \
line[147:148] + "." + line[148:150] + "," + \
line[150:152] + "," + line[152:154] + "," + line[154:156] + "," + \
line[156:158] + "." + line[158:160] + "," + \
line[160:162] + "." + line[162:164] + "," + \
line[164:168] + "," + line[168:169] + "," + line[169:177] + "," + \
line[177:185] + "," + line[185:188] + "," + line[188:191] + "," + \
line[191:194] + "," + line[194:197] + "," + line[197:200] + "," + \
line[200:203] + "," + line[203:206] + "," + line[206:208] + "," + \
line[208:210] + "," + line[210:212] + "," + line[212:214] + "," + \
line[214:216] + "," + line[216:218] + "," + line[218:220] + "," + \
line[220:222] + "," + line[222:225] + "," + line[225:228] + "," + \
line[228:231] + "," + line[231:234] + "," + line[234:237] + "," + \
line[237:240] + "," + line[240:242] + "," + line[242:244] + "," + \
line[244:246] + "," + line[246:248] + "," + line[248:250] + "," + \
line[250:252] + "," + line[252:254] + "," + line[254:256] + "," + \
line[256:259] + "," + line[259:262] + "," + line[262:265] + "," + \
line[265:268] + "," + line[268:271] + "," + line[271:274] + "," + \
line[274:276] + "," + line[276:278] + "," + line[278:280] + "," + \
line[280:282] + "," + line[282:284] + "," + line[284:286] + "," + \
line[286:288] + "," + line[288:290] + "," + line[290:293] + "," + \
line[293:296] + "," + line[296:299] + "," + line[299:302] + "," + \
line[302:305] + "," + line[305:308] + "," + line[308:310] + "," + \
line[310:312] + "," + line[312:314] + "," + line[314:316] + "," + \
line[316:318] + "," + line[318:320] + "," + line[320:322] + "," + \
line[322:324] + "," + line[324:327] + "," + line[327:330] + "," + \
line[330:333] + "," + line[333:336] + "," + line[336:339] + "," + \
line[339:342] + "," + line[342:344] + "," + line[344:346] + "," + \
line[346:348] + "," + line[348:350] + "," + line[350:352] + "," + \
line[352:354] + "," + line[354:356] + "," + line[356:358] + "," + \
line[358:361] + "," + line[361:364] + "," + line[364:367] + "," + \
line[367:370] + "," + line[370:373] + "," + line[373:376] + "," + \
line[376:378] + "," + line[378:380] + "," + line[380:382] + "," + \
line[382:384] + "," + line[384:386] + "," + line[386:388] + "," + \
line[388:390] + "," + line[390:392] + "," + line[392:394] + "," + \
line[394:396] + "," + line[396:398] + "," + line[398:400] + "," + \
line[400:403].replace(' ', '') + "\n"
# 抽出したデータをCSVファイルに書き込む
csv_file.write(racer_data)
# 次の行を読み込む
line = text_file.readline()
# CSVファイルを閉じる
csv_file.close()
# 開始合図
print("作業を開始します")
# CSVファイルを保存するフォルダを作成
os.makedirs(CSV_FILE_DIR, exist_ok=True)
# CSVファイルを作成しヘッダ情報を書き込む
csv_file = open(CSV_FILE_DIR + CSV_FILE_NAME, "w", encoding="shift_jis")
csv_file.write(CSV_FILE_HEADER)
csv_file.close()
# テキストファイルのリストを取得
text_file_list = os.listdir(TEXT_FILE_DIR)
# リストからファイル名を順に取り出す
for text_file_name in text_file_list:
# 拡張子が txt のファイルに対してのみ実行
if re.search(".txt", text_file_name):
# テキストファイルを開く
text_file = open(TEXT_FILE_DIR + text_file_name, "r", encoding="shift_jis")
# 関数 get_data にファイル(オブジェクト)を渡す
get_data(text_file)
# テキストファイルを閉じる
text_file.close()
print(CSV_FILE_DIR + CSV_FILE_NAME + " を作成しました")
# 終了合図
print("作業を終了しました")
分析例
キョーコはレーサー期別成績を利用して、レーサーごとに級別の変化を表現していました。これは視覚的に優れていますので、ぜひ見てあげてください。
レーサー期別成績には、級別の他にも誕生日や血液型といったマニアックな情報も入っており、競走成績や番組表とは色の違う分析ができそうですね。
次の分析例では、単純に身長と体重からBMIを計算してヒストグラムを作っています。Googleスプレッドシートを使えば簡単にヒストグラムを作成できます。
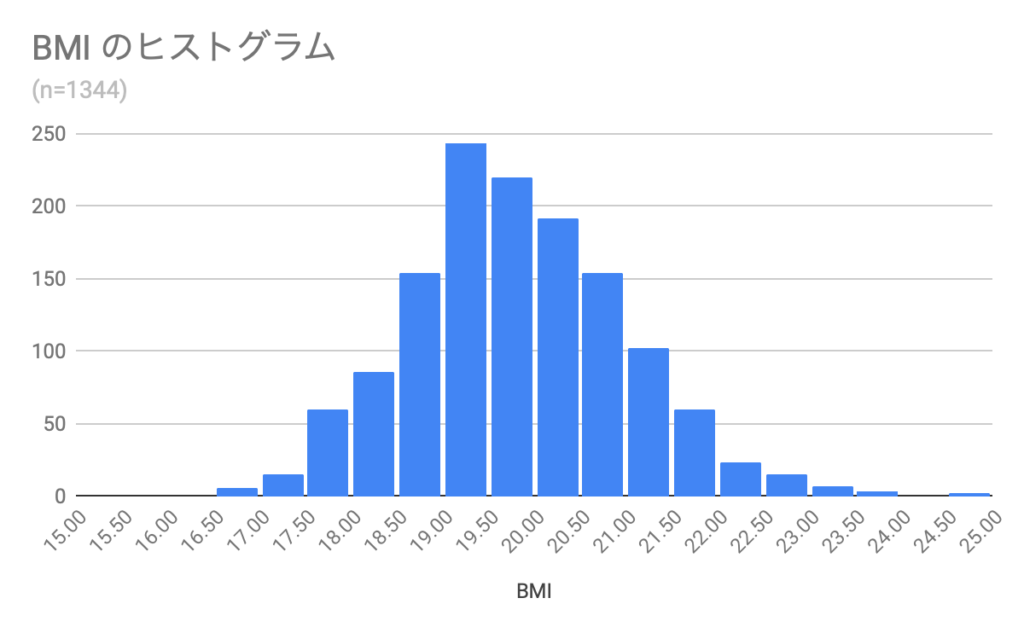
きれいなつりがね型ですね。このデータは2010のファイルです。対象は男性レーサーだけで、勝率が0より大きい人だけとしています。平均値は19.83でした。
これだけでは面白くないので、BMIと勝率を使って散布図を作成してみます。散布図とは、2つの変数の関係性を表現するのに適したグラフです。
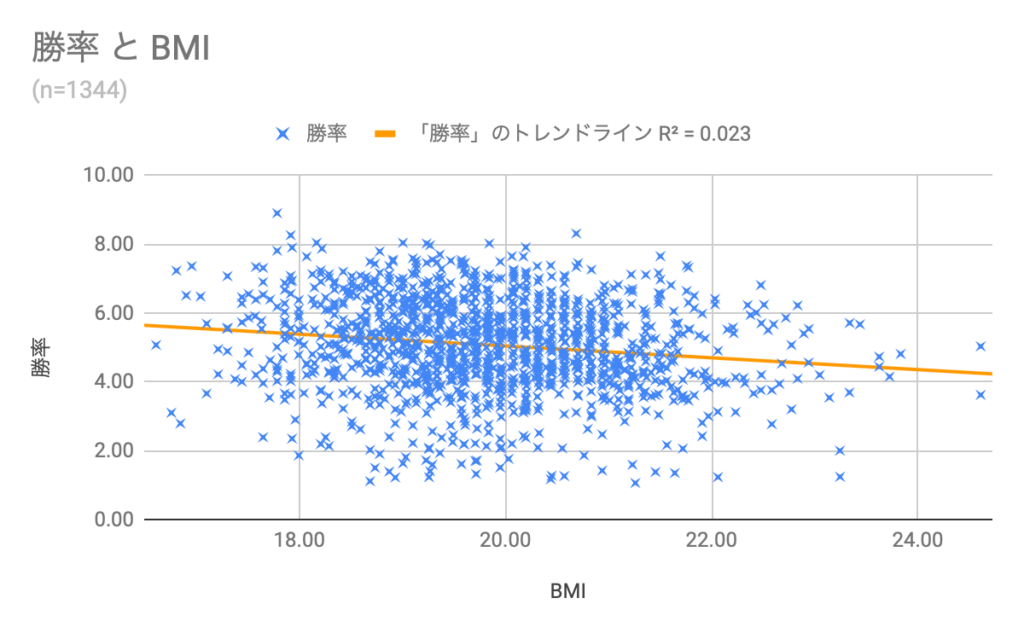
結論から言うと、BMIは勝率にあまり関係しないようです。まぁ、そうですよね。
回帰直線(トレンドライン)は右肩下がりですので、BMIが高いと勝率が下がるように見えますが、決定係数(R^2)が0.023と低いため、相関関係はほぼないと言えます。
レーサー期別成績には、この他にも面白そうなデータがたくさん入っていますので、ぜひ活用してみましょう。

